

티스토리 뷰
AWS를 이용한 데이터 엔지니어링(8) - Redshift & 최적화 전략
코딩하는 제리코 2026. 4. 2. 18:389-1. Redshift 소개
OLTP vs OLAP
| OLTP | OLAP | |
| 명칭 | Online Transaction Processing | Online Analytical Processing |
| 핵심 | 쓰기(INSERT/UPDATE) | 읽기 (SELECT) |
| 목적 | 빠른 트랜잭션 및 데이터 수정 | 복잡한 분석 및 의사 결정 지원 |
| 데이터 성격 | 실시간 데이터 처리 | 데이터 분석 |
| 주요 연산 | CRUD 연산 | GROUP BY, JOIN, AGGREGATE |
| 데이터 크기 | 상대적으로 작음 | 매우 큼 |
| 데이터 무결성 | ACID 준수 | 일부 희생 |
| 사용 사례 | 은행 거래, 주문처리 | 데이터 웨어하우스, BI |
왜 OLAP는 ACID를 일부 희생할까?
1. 빠른 분석이 더 중요하고
2. 약간의 데이터 지연 허용 가능하기 때문
Data Warehouse
분석을 위해 정제된 데이터만 모아놓은 저장소
- 분석을 위해 최적화된 중앙 저장소
- 다양한 소스 데이터를 통합, 저장, 관리
- 대용량 데이터 처리 가능
- BI 활동을 지원하기 위해 설계됨
- Amazon Reshift, Google BigQuery 등
Redshift
AWS의 완전 관리형 OLAP 데이터 웨어하우스

- PB 규모의 스토리지 지원
- OLAP 디자인, MPP 구조
- SQL 지원
- 다양한 AWS 서비스와의 통합
- ML, Serverless
- 통합 데이터 웨어하우스, 데이터 분석
Redshift Architecture

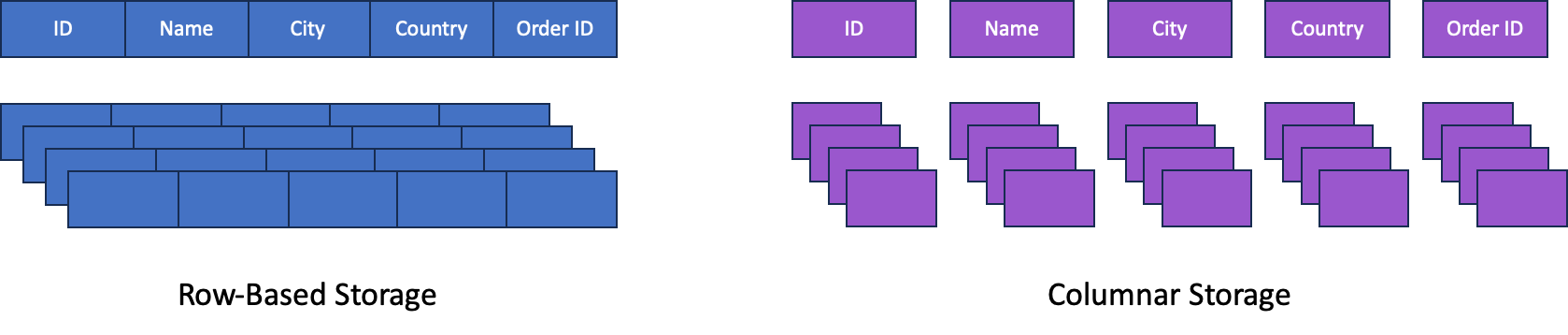
1) Redshift 아키텍쳐의 특징 - Columnar Storage
- 컬럼 단위로 데이터를 읽고 씀
- 필요한 칼럼만 읽어서 성능 향상
2) Redshift 아키텍쳐의 특징 - MPP 구조
여러 서버가 나눠서 동시에 처리하는 구조
- Massively Parallel Processing
- 대용량 데이터 병렬 처리
- 여러 컴퓨팅 노드를 이용
- 아래사진 부연 설명
- Client 가 쿼리를 하면 Leader node에 의해 각 노드로 쿼리 분산
- 각 노드는 역할에 맞는 역할 수행
- 수행된 결과들을 다시 Leader node로 취합
- Leader node가 Client로 결과를 반환

SQL
- Postgres 쿼리 엔진 기반 실행
- CRUD
- SELECT, JOIN, AGGREGATION 가능
- 다른 AWS와 통합
1) 시스템 테이블 / 뷰
| 접두사 | 설명 | 예 |
| SVV_ | 객체에 대한 정보 포함하는 시스템 뷰 | SVV_TABLE_INFO |
| SYS_ | 쿼리 및 리소스 사용량을 모니터링하는 시스템 뷰 | SYS_QUERY_DETAIL |
| STL_ | 실행 로깅을 위한 시스템 뷰 | STL_SCAN |
| STV_ | 시스템 데이터의 스냅샷을 포함하는 가상 시스템 테이블 | STV_LOCKS |
| SVCS_ | 클러스터 내 모든 쿼리의 세부 정보 제공하는 시스템 뷰 | SVCS_EXPLAIN |
| SVL_ | STL 로그를 보기 쉽게 정리한 시스템 뷰 | SVL_QUERY_REPORT |
| PG_ | 테이블/스키마/유저 등 메타데이터 테이블 | PG_TABLE_DEF |
9-2. Importing & Exporting Data
Importing Data
데이터 적재 방법
- INSERT INTO를 활용한 적재
- COPY 명령어를 활용한 적재
- 병렬 처리
- S3, EMR, DynamoDB 등
- 다른 서비스와 통합
- Glue ETL을 이용한 적재
- Kinesis or MSK
Copy 명령어
S3등의 데이터를 Redshift로 대량, 빠르게 적재하는 명령어
1) 필수 작성
- COPY: Target 테이블 지정
- FROM: 데이터 소스 지정
- 's3://…', 'dynamodb://…', 'emr://…'
- Authorization
- 권한 설정
- IAM_ROLE
2) 옵션
- FORMAT AS : 데이터 포맷
- CSV, JSON, PARQUET 등
- Parameter
- DELIMITER(구분자 지정), IGNOREHEADER(첫줄에 있는걸 헤더로 지정할지 여부)
- MANIFEST, GZIP
COPY table-name
[ column-list ]
FROM data_source
authorization
[ [ FORMAT ] [ AS ] data_format ]
[ parameter [ argument ] [, ... ] ]
3) COPY명령어 사용할때 최적화 방법들
- S3 파일 여러 개로 쪼개기 (100MB ~ 1GB) -> 병렬처리 하기 때문이다.
- 압축 사용 (GZIP, BZIP2, LZO)
- COMPUPDATE OFF 설정 (컬럼 단위로 통계를 업데이트 하는 기능)
- STATUPDATE OFF 설정 (테이블에 대한 통계를 업데이트 하는 기능)
- 테이블 컬럼과 입력 파일 컬럼 순서 및 타입 맞추기 (Redshift 에서 타입캐스팅이 일어나기 때문에 맞춰줘야함)
Exporting Data
UNLOAD 명령어를 이용한 데이터 추출
1) 필수 작성
- UNLOAD: 추출할 SELECT 쿼리 설정
- TO: S3 위치 설정
- AUTHORIZATION
- 권한 설정
- IAM_ROLE
2) 옵션
- FORMAT AS : 데이터 포맷
- CSV, JSON, PARQUET 등
- ALLOWOVERWRITE / CLEANPATH
- 압축 방식 (GZIP, BZIP2, ZSTD, …)
UNLOAD (
'select-statement'
)
TO 's3://object-path/prefix'
Authorization
[ option, … ]9-3. Datashare & Spectrum
Data Sharing
클러스터(Redshift)간에 실시간 데이터 공유하는 기능
만약 Data Sharing이 없었더라면 데이터 공유를 어떻게 했을까?
1. 한쪽 클러스터에서 unload 명령어로 데이터를 추출하고
2. 다른 클러스터에서 해당 데이터를 copy 데이터로 적재한다.
=> 이렇게 하니까 아래와 같은 문제가 발생했다.
1. 데이터를 unload 하고 copy하는 컴퓨팅적 비용과 시간이 비효율
2. 동일한 데이터들을 클러스터마다 저장하게 되는 문제가 발생
3. 특정 클러스터에만 데이터를 저장하는 경우에 데이터 품질에 문제가 있을 수 있음(한쪽 클러스터에서는 데이터를 수정했는데 이 데이터를 copy한 다른 클러스터에는 최신화 되지 않은 경우)
- 복사 없이 조회 가능
-
Cross-account, Cross-region 지원
-
RA3 노드 타입 또는 Serverless에서만 지원함
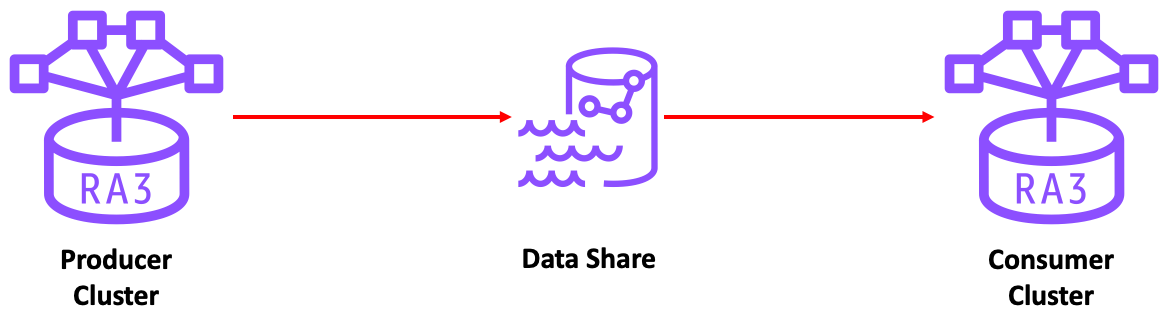
1. Producer Cluster(데이터를 제공해주는 클러스터) 와 Consumer Cluster(데이터를 전달 받는 클러스터)를 결정한다.
2. 제공하고자 하는 데이터에 대한 스키마와 테이블을 Data Share에 등록한다.
3. Consumer Cluster에서 이 등록한 스키마와 테이블을 구독한다.
=> 이러한 절차를 통해서 Producer Cluster에서 데이터의 수정이나 등록이 발생하면
Data Share를 통해 Consumer Cluster에도 반영되게 된다.
아래는 이러한 과정을 쿼리로 볼 수 있도록 정리된 그림이다.

시스템 뷰
정상적으로 등록이 되었는지 확인하는 방법
| View Name | 설명 |
| SVV_DATASHARES | Datashare 목록 및 속성 |
| SVV_DATASHARE_OBJECTS | Datashare에 등록된 스키마와 테이블 목록 |
| SVV_DATASHARE_CONSUMERS | Datashare을 구독하는 Consumer 클러스터 정보 |
| SVV_DATASHARE_PRIVILEGES | Datashare에 대한 권한 정보 |
Redshift Spectrum
S3 데이터를 옮기기 않고 직접 읽는 기능
기존 방식
1. S3 (데이터 있음)
2. Redshift로 Copy해서 적재
3. SQL 조회
이렇게 하다보니까 아래와 같은 문제가 있었음
1. 데이터 복사 필요
2. ETL 작업 필요
3. 실시간 데이터 반영 어려움
따라서 그냥 S3 -> Redshift로 직접 조회 하는 Spectrum 기능이 있는것.

- 무한한 동시성
- 스토리지 & 컴퓨팅 리소스 분리
- 다양한 데이터 포맷 지원
- 스캔한 데이터 양에 따라 과금

구성별 설명
- S3: 데이터 저장
- Glue: 데이터 구조 정의
- External Schema: 연결 통로
- Redshift: SQL 실행
쿼리 설명 (1)
- CREATE EXTERNAM SCHEMA: Redshift 안에 외부 데이터용 폴더를 만듬
- FROM data catalog: Glue Data Catalog 사용 (S3 데이터의 설명서)
- DATABASE '이름': Glue 안에 있는 DB 선택
- IAM_ROLE: S3 접근 권한
- CREATE EXTERNAL DATABASE IF NOT EXISTS: Glue DB 없으면 생성
- 총 정리: Glue에 있는 S3 데이터를 Redshift에서 쓸 수 있게 연결한다
쿼리 설명 (2)
- CREATE EXTERNAL TABLE: 외부(S3) 데이터 테이블 생성
- [스키마].[테이블]: 위에서 만든 external schema 안에 테이블을 생성
- ROW FORMAT SERDE: 파일 읽는 방법 정의
- LOCATION: 실제 데이터 위치
- 총 정리: 이 S3 경로 데이터를 이 구조로 읽겠다.
9-5. Datashare & Spectrum 실습
1) producer, consumer 클러스터 생성
우선 producer, consumer 용 redshift 클러스터 두개를 생성하였다.

2) 생성한 클러스터를 DBeaver에 연결해서 datashare 생성 쿼리 작성
1. 우선 아래 쿼리를 실행하여 S3 데이터를 COPY 해왔다.
-- 스키마 생성
CREATE SCHEMA metacode;
-- 테이블 생성
CREATE TABLE metacode.order_data (
member_id VARCHAR(10),
product_id VARCHAR(10),
order_quantity INT,
order_price BIGINT
);
-- 테이블 확인
SELECT *
FROM metacode.order_data;
-- 데이터 적재
COPY metacode.order_data
FROM 's3://버킷명 모자이크/order_data_automatic_mapping/'
IAM_ROLE 'arn:aws:iam::모자이크:role/role_redshift_s3'
FORMAT AS JSON 'auto';
2. datashare 생성하고 스키마와 테이블 생성
-- Datashare 생성
create dataSHARE metacode_datashare;
-- Datashare에 Schema 추가
alter DATASHARE metacode_datashare
add schema metacode;
-- Datashare에 테이블 추가
alter DATASHARE metacode_datashare
add table metacode.order_data;
3. 생성된 datashare가 정상적으로 등록되었는지 시스템 뷰로 확인
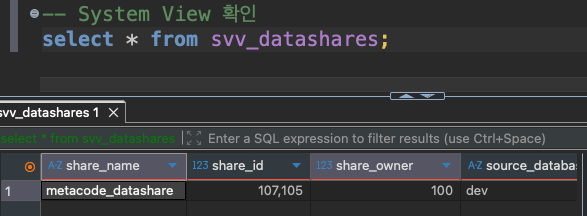
아래 시스템 뷰를 통해 알수 있는것은
share_type이 OUTBOUND 인것은 producer 클러스터라는 뜻이다.

4. 권한 부여
namespace에는 consumer 쪽 namespace를 넣어야하는데,
-- 권한 부여
grant usage on DATASHARE metacode_datashare to namespace '{여기에는 consumer 쪽 name_space를 넣어야함}',
consumer 클러스터에서 SQL로 아래 쿼리를 실행시킨뒤 나오는 namespace를 복붙해서 넣어도 되고,
select current_namespace;
Redshift 클러스터 정보에 담긴 namespace를 넣어도 된다.
5. Consumer 클러스터 작업 - Datashare 용 데이터 베이스 생성
아래 쿼리를 통해 Datashare 용 데이터 베이스를 생성하면 되는데,
-- Datashare 용 데이터 베이스 생성
create database metacode_datashare_db
from DATASHARE metacode_datashare
of account '{producer 클러스터의 account}'
namespace '{producer 클러스터의 namespace}';
이때 producer 클러스터의 account 와 namespace는 아래 시스템뷰를 통해 알 수 있다.
-- ACCOUNT, NAMESPACE 정보 확인
select * from svv_datashares;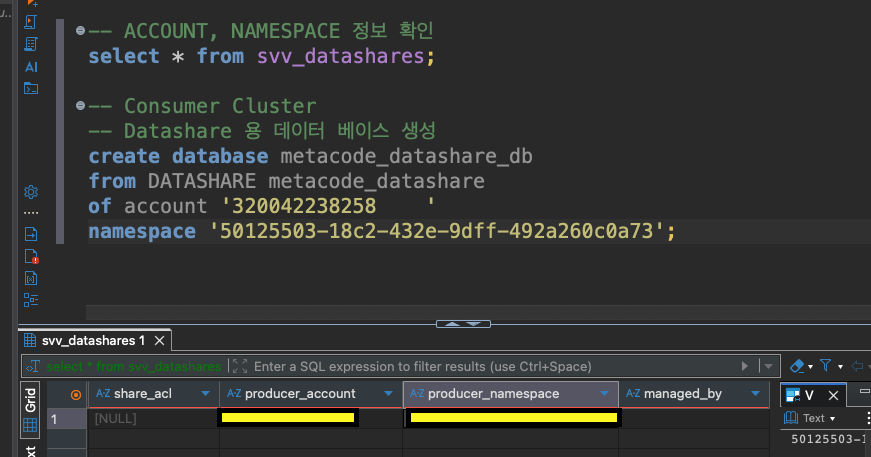
이거도 마찬가지로 Redshift 에서도 알 수있다.
여기 까지 하고 다시 svv_datashares 를 보게 되면
아래와 같이 consumer_databes에 db가 잘 보이게 된다.
즉, '이제 이 consumer 클러스터에서는 해당 DB를 구독한다' 라는 뜻이기도 하다.

6. Datashare Table 확인
아래 쿼리를 통해 Datashare 의 테이블을 확인하려고 하였다
-- Datashare Table 확인
select * from metacode_datashare_db.metacode.order_data;근데 이런.. 아래와 같은 에러가 뜨게 되었다.

위와 같은 에러가 뜨게 된 이유는
producer 클러스터에서 datashare가 public access 가 되도록 설정을 해줘야하는데 하지 않았기 때문이다.
따라서 producer 클러스터에서 아래 명령어를 입력하면 된다.
alter datashare metacode_datashare set publicaccessible=true;
사실 같은 리전내에 두개의 클러스터(producer, consumer)를 생성했기 때문에
public access가 기본값인 false여도 문제없이 동작했어야하는 것이 맞지만,
실습하면서 클러스터를 DBeaver에 연결하려고 수동으로 클러스터의 퍼블릭 액세스 기능을 Turned on으로 해놨기 때문에 발생하였다.

public access 허용하니까 이제 테이블이 잘 보인다.
3) Spcectrum 실습
Spectrum 실습은 producer, consumer 아무데서나 진행하면 된다.
1. External Schema 생성
아래 쿼리를 통해 External Schema를 생성하는데,
database에는 내가 glue에서 생성했던 database 이름을 찾아서 기입해줬다.
-- External Schema 생성
create external schema metacode_external
from data catalog
database 'test'
IAM_ROLE 'arn:aws:iam::내 프라이버시:role/role_redshift_s3'
create external database if not exists;
이렇게 되면 굉장히 편하게
glue database 안에 있는 테이블을 별도로 연동안해도 쿼리할 수 있게 된다.

9-6. Redshift 성능 최적화 전략
- DISTKEY, SORTKEY 활용
- 데이터 정리 및 최적화
- VACUUM, ANALYZE
- Workload Management (WLM) 설정
DISTSTYLE
데이터를 컴퓨팅 노드에 어떻게 분산할지를 정하는 것
사용하는 이유
같은 노드에 데이터를 위치시켜서
1. 네트워크 이동을 줄이고
2. JOIN 속도를 늘림
데이터 분산 스타일
- AUTO, EVEN, KEY, ALL
1. AUTO
- Redshift 에서 자체적으로 판단해서 분산하는 방법
2. EVEN
- 모든 노드에 동등하게 데이터를 분산시키는 방법
3. KEY
- Key를 통해서 지정된 칼럼의 데이터로 분배하는 방법
- Key를 잘못 등록하면 한쪽 노드에 데이터가 몰리는 문제가 발생 할 수 있어 Key를 잘 등록해야함
4. ALL
- 모든 노드에 전체 데이터를 복사해서 가지고 있는 방법
- 큰 테이블을 사용하는 경우에는 메모리 낭비가 심각할 수 있음
SORTKEY
데이터를 어떻게 정렬할지 기준
- 정렬키
- 데이터를 정렬하여 디스크에 저장하는 방식
- 종류
필요한 데이터만 빠르게 탐색하기 위해 필요
| SORTKEY | 설명 | 특징 |
| COMPOUND SORT KEY | 지정한 컬럼 순서대로 정렬 | WHERE 조건의 컬럼이 SORT KEY 맨 앞에 있으면 성능이 매우 좋음 |
| INTERLEAVED SORT KEY | 지정한 컬럼들을 동등하게 정렬 | WHERE 조건에서 다양한 컬럼이 골고루 사용될 때 좋음 |
| AUTO SORT KEY | Redshift가 자동으로 분석하고 적절한 컬럼으로 설정 | 테이블 설계에 신경쓰지 않아도 되지만 제어가 불가능함 |
사실 표만으로는 이해하기가 어렵기 때문에 예를 들어서 설명을 해보겠다.
예를들어 (날짜, 카테고리) 순서로 Compound Sort Key를 지정했다고 가정해보자.
이렇게 되면 우선 무조건 '날짜' 순서대로 정렬하고 날짜가 같은 데이터 안에서만 '카테고리' 순서로 정렬한다.
그럼 날짜순서대로 우선 데이터들이 정렬될거기 때문에,
위 표의 특징에 적혀 있는 대로 SORT KEY 맨 앞 곧 '날짜'로 되어 있으면 성능이 좋다는 거다.
그다음으로 (날짜, 카테고리)를 Interleaved 로 지정하게 되면,
데이터가 날짜와 카테고리를 동시에 고려한 모자이크 격자 무늬처럼 저장된다.
그래서 날짜로 찾든, 카테고리로 찾든 극단적으로 빠르거나 느리지 않는다.
Compound 방식처럼 날짜를 검색할때 한번만에 찾지는 못하고 한 3번 정도 뒤져야하지만,
카테고리로 찾을때도 전체를 다 뒤지지 않고 3번만 뒤지면 찾을 수 있다는 것이다.
다만 테이블이 커지면 자연스럽데 성능이 떨어질 수 있다.
'아 어떤 컬럼으로 검색학지 아직 모르겠다' 할때 Redshift가 그동안 유저들이 쿼리 날린 통계를 분석해서
알아서 Compound나 Interleaved 중에 골라주는 기능이 AUTO SORT KEY 기능인것이다.
다만 제어가 불가능한 단점이있다.
VACUUM
지저분해진 데이터를 정리
just like, 파일을 삭제하면 휴지통에 들어가지만 휴지통 비우기를 하지 않으면 용량이 확보되지 않는 것과 같은것
휴지통 비우기를 하는 명령어 라고 생각하면 이해가 편할듯
- 필요한 이유
- Redshift는 UPDATE/DELETE 하면 데이터가 '삭제 표시만 됨'
- 따라서 공간낭비, 정렬 깨짐과 같은 문제가 있는데,
- 이를 VACCUM으로 정리하는 것
- 명령
- VACUUM FULL: 삭제된 데이터 정리 + 정렬
- VACUUM DELETE ONLY: 삭제된 데이터만 정리
- VACUUM SORT ONLY: 정렬만 수행 -> 쿼리 성능 향상 가능
- VACUUM REINDEX: Interleaved sort key 재정렬
- 주의할 점
- VACUUM 실행 중에는 데이터에 대한 정리 작업이 이뤄지기 때문에 클러스터의 성능 저하 가능
- 따라서 트래픽이 몰리지 않는 시점에 하는게 좋음
- 실제로 데이터를 적재하고 나서 적재된 데이터의 정렬 상태를 최신화하기 위해서 사용하기도 함.
ANALYZE
쿼리 성능을 위한 통계 업데이트
- 통계 정보 최신화
- 쿼리 옵티마이저 성능 향상 (최신화된 통계를 가지고 있어야 하기 때문)
- INSERT / DELETE / UPDATE가 많은 경우 사용 (데이터의 변화가 많아지기 때문에)
- 주기적으로 실행이 필요함
- 또는 대량의 데이터가 적재되거나 업데이트 됐을때 실행하게 됨
WLM
쿼리 리소스 스케줄러
예를들어
짧은 쿼리가 긴 쿼리 뒤 스케줄에 있으면 짧은 쿼리지만 늦게 실행되게 되는 문제가 발생한다.
이러한 케이스를 해결해주는것을 WLM
- 사용하는 이유
- 쿼리 리소스를 효율적으로 분배하고 관리 (충돌되지 않도록)
- 동작 방식
- 쿼리 큐
- 무거운 쿼리와 가벼운 쿼리가 같은 줄에 서면 문제가 생기니까
- Redshift는 여러개의 큐(대기열)을 만들어서 그 두개의 쿼리를 분리하게 되는것
- 쿼리 라우팅
- 사용자가 쿼리를 날리면 WLM이 쿼리의 성격이나 쿼리를 날린 사용자 그룹(일반 유저 vs 관리자)을 판단하여 알맞은 큐로 전달함
- 슬롯
- 하나의 큐안에 배치된 계산원(?)의 수
- 예를들어 특정 큐 안에 슬롯이 5개라면 그 큐에서는 동시의 5개의 쿼리를 병렬로 처리할 수 있다는 뜻
- 다만 너무 많이 쪼개면 슬롯 하나당 배정되는 메모리가 줄어들어 오히려 쿼리 처리 속도가 느려질 수 있음
- Concurrency Scaling
- 트래픽이 폭주해서 모든 큐와 슬롯이 꽉 차고 대기 줄이 끝없이 길어질 때 발동하는 비장의 무기(?)
- AWS가 백그라운드에서 임시 Redshift 클러스터를 순식간에 띄워서 밀려있는 쿼리들을 그쪽으로 빼서 처리.
- 밀린 작업이 끝나면 임시 클러스터는 알아서 사라짐.
- 과금의 위험성이 있어서 필요할 때만 켜두어야함
- 쿼리 큐
- 관리 방식
- 자동 WLM
- 수동 WLM
'DataEngineer(DE) > AWS를 이용한 데이터 엔지니어링' 카테고리의 다른 글
| AWS를 이용한 데이터 엔지니어링(10) - EMR & MWAA & Kinesis & MSK (0) | 2026.04.03 |
|---|---|
| AWS를 이용한 데이터 엔지니어링(9) - QuickSight (0) | 2026.04.03 |
| AWS를 이용한 데이터 엔지니어링(7) - Lambda (0) | 2026.03.31 |
| AWS를 이용한 데이터 엔지니어링(6) - Athena & Athena 최적화 전략 (0) | 2026.03.30 |
| AWS를 이용한 데이터 엔지니어링(5) - Glue, Data Catalog, Glue ETL (0) | 2026.03.28 |
- Total
- Today
- Yesterday
- Data Dngineering
- AWS Glue Catalog
- Spark structured streaming
- RDD
- Data Pipeline
- lake house
- Daynamic Task
- Consumer DAG
- docker
- iceberg
- Glue ETL
- Data engineering
- spark
- AWS
- elasticip
- Data Engineerring
- Backfill
- DAG
- s3
- airflow
- lakehouse
- Prodcuder DAG
- 데이터파이프라인
- DataSet
- Unity Catalog
- kafka
- catchup
- Databricks
- de
- Glue
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |