

티스토리 뷰
DataEngineer(DE)/AWS를 이용한 데이터 엔지니어링
AWS를 이용한 데이터 엔지니어링(10) - EMR & MWAA & Kinesis & MSK
코딩하는 제리코 2026. 4. 3. 20:2811-1. EMR 소개
EMR
EMR은 거대한 데이터를 병렬로 쪼개서 빠른 속도로 처리해 주는 서비스
Hadoop, Spark 같은 빅데이터 오픈소스를 AWS 환경에서 클릭 몇 번으로 쉽게 쓸 수 있는 서비스

- Elastic MapReduce
- 대규모 데이터 처리 및 분석 플랫폼 서비스
- 관리형 Hadoop 프레임워크 사용
- 대표적인 오픈소스 툴
- Apache Hadoop: 분산 처리 프레임워크
- Apache Spark: 대용량 데이터 병렬 처리
- Apache Hive: SQL을 이용한 데이터 분석
- Presto: 빠른 SQL 쿼리 엔진
- Apache Yarn: 리소스 매니저
- EC2, Serverless, EKS
- 대규모 ETL, 데이터 파이프라인, 머신러닝 에서 주로 사용됨
클러스터 구성 요소
- Master Node
- Leader Node
- 클러스터 및 Task 관리 및 스케줄링
- Single Instance (Ondemand)
- Core Node
- 데이터 처리 Task 실행
- 분산 데이터 저장
- Ondemand + Spot (다만 주로 추천)
- 데이터가 저장되어 있기 때문에 중간에 종료되면 데이터가 날아갈 수 있기 때문
- Task Node
- 데이터 저장 없이 Task(데이터 처리-연산) 실행
- Spot Instance 사용 추천
- 일이 몰릴 때 저렴한 스팟 인스턴스(Spot)로 우르르 사용하다가 일 끝나고 바로 종료
✅ 온디멘드(On-Demand) vs 스팟(Spot) ...feat. gemini
1. 온디맨드 (On-Demand) = 정가 내고 쓰는 '일반 지정석'
- 개념:
내가 원할 때(On-Demand) 언제든지 켜서 쓰고, 쓴 시간만큼 정가를 내는 가장 기본적인 방식
- 장점 (안정성):
끄지 않으면 꺼지지 않으므로 안정성이 높다.
- 단점 (비용):
정가를 다 줘야 하므로 요금이 꽤 비쌈
- 언제 쓰는가?
중간에 절대 꺼지면 안 되는 중요한 작업, EMR의 'Master 노드'나 데이터를 꽉 쥐고 있는 'Core 노드'에 사용
2. 스팟 (Spot) = 파격 할인가에 쓰는 '눈치 게임석'
- 개념:
PC방 사장님(AWS) 입장에서, 손님이 없어서 노는 빈자리들이 아깝습니다. 그래서 "빈자리 남을 때만 쓰면 정가에서 최대 90%까지 깎아줄게!" 하고 내놓은 초특가 요금제입니다.
- 장점 (비용):
온디맨드에 비해 가격이 미친 듯이 쌉니다. (보통 70~90% 저렴)
- 단점 (강제 종료):
치명적인 단점이 있습니다. 갑자기 정가를 내겠다는 온디맨드 손님들이 몰려오면, 사장님은 스팟 요금제 손님에게 다가가 이렇게 말합니다. "손님, 2분 뒤에 컴퓨터 꺼집니다. 저장하고 비켜주세요." (이것을 '스팟 인터럽션(Spot Interruption)'이라고 부릅니다.)
- 언제 쓰는가?
중간에 컴퓨터가 꺼져도 큰일 나지 않는 단순 반복 작업에 씁니다. 앞서 설명한 EMR의 'Task 노드(단기 알바생)'가 딱 제격입니다. 연산하다가 쫓겨나면? 나중에 다른 빈자리가 났을 때 마저 이어서 계산하면 되니까요!
인스턴스 리소스 구성 방식
1. 인스턴스 그룹 (Instance Group)
전통적인 방식이며, 가장 직관적임
- 방식: 마스터, 코어, 태스크 각각의 그룹에 딱 한 종류의 인스턴스 모델만 정합니다. (예: 마스터는 m5.xlarge, 코어는 r5.2xlarge)
- 특징: 설정이 아주 단순합니다. "코어 노드 10대 더 늘려줘"라고 하면 내가 정한 그 모델로만 10대가 늘어납니다.
- 단점: 만약 내가 찍은 그 모델(m5.xlarge)이 해당 데이터 센터에 재고가 없거나, 스팟 가격이 폭등하면 대안이 없습니다. 그냥 작업이 실패하거나 비싼 돈을 내야 합니다.
- 적합한 상황: 소규모 클러스터나, 반드시 특정 사양의 컴퓨터가 필요한 경우에 씁니다.
2. 인스턴스 플릿 (Instance Fleet)
최근 대규모 데이터 처리에서 권장되는 유연한 방식입니다.
- 방식: 모델 하나를 찍는 게 아니라, "이런 사양의 컴퓨터들이면 아무거나 좋아"라고 리스트를 줍니다. (예: m5.xlarge, m5.2xlarge, r5.xlarge 중 남는 거 아무거나 줘)
- 특징 (대상 용량): 대수(Count)가 아니라 '용량 점수(Target Capacity)' 개념을 씁니다. m5.xlarge는 1점, m5.2xlarge는 2점으로 정해두고 "총 10점어치 뽑아줘"라고 하면 AWS가 재고 상황에 맞춰 섞어서 뽑아줍니다.
- 장점: 스팟 인스턴스를 쓸 때 최고입니다. A 모델이 품절되면 자동으로 B 모델을 찾아주기 때문에 클러스터가 갑자기 꺼질 확률이 확 줄어듭니다.
- 적합한 상황: 대규모 클러스터, 스팟 인스턴스를 적극적으로 활용해 비용을 아끼고 싶을 때 씁니다.
| Instance Group | Instance Fleet | |
| 특징 | - Master, Core, Task 노드를 각각 하나의 그룹으로 정의 - 각 그룹마다 인스턴스 타입, 개수, 스팟/온디멘드 여부 개별 지정 - Core, Task 인스턴스 변화가 탄력적이지 않음(미리 지정하고 쓰다 보니까) |
- Master, Core, Task에 대해 여러 인스턴스 타입, AZ, 스팟/온디멘드 비율을 묶어서 구성 - AWS가 실시간으로 저렴하고 안정적인 인스턴스를 할당 - 스팟 인스턴스 용량이 부족할 경우 자동으로 다른 타입 또는 다른 AZ로 대체 |
| 장점 | - 설정이 간단하고 직관적 - 작은 규모 클러스터에 유용 |
- 멀티 타입, AZ 지원 - 스팟 인스턴스 Interruption 최소화 - 큰 규모의 클러스터, 비용 최적화 |
| 단점 | - 인스턴스 타입을 다양하게 혼합하기 어려움 - 자동화/최적화 기능이 부족함 |
- 설정이 더 복잡합 - 정해진 인스턴스 타입과 우선순위 전략 |
EMR에서의 클러스터 활용
EMR은 결코 싸지 않기때문에 잘 활용해야함
- Transient Cluster
- EMR 프로세스 완료되면 Terminate (클러스터 삭제)
- 프로세스가 진행될때만 사용하기 때문에 비용 절감
- Long-Running Cluster
- 사용하는 파이프라인이 많아서 항상 돌아가는 경우에 사용
- 24시간 지속적인 실행
- 따라서 적절한 인스턴스 스펙을 잘 골라서 사용해야함
EMR에서의 스토리지
- HDFS
- Hadoop Distributed File System
- 성능이 빠름
- 클러스터를 terminate 하게되면 데이터 유실 가능성
- 캐시 데이터
- EMRFS
- S3 데이터 읽고 쓰기
- 데이터 유실 X
- Local
- 임시 데이터(버퍼, 캐시 등)에만 적합함
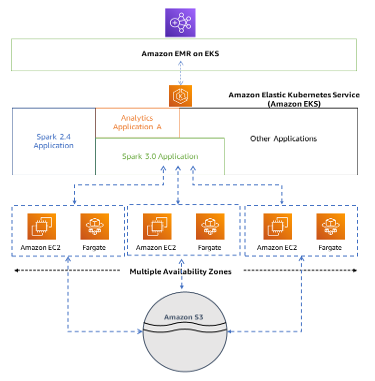
EKS 에서 구성하는 EMS
- Elastic Kubernetes Service
- Spark Job을 EKS로 제출함
- 완전 관리형
- 다른 애플리케이션과 자원 공유
- EC2 에 비해 시간도 줄고 시간, 비용 면에서 좀더 효율적일 수 있음
11-2. MWAA 소개
✅ Gemini 에게 물어본 MWAA 한줄 정리
MWAA(Airflow)는 본인이 직접 무거운 데이터를 나르거나 연산하지 않습니다. 그저 지휘자일 뿐입니다. "야, EMR! 너 지금 S3에서 데이터 가져와서 가공해. 끝났어? 그럼 Redshift! 너가 지금 그거 가져가서 적재해!" 하고 다른 AWS 서비스들에게 명령을 내리고 모니터링하는 역할을 합니다.

Apache Airflow
추후 포스팅으로 Airflow 집중공략할거기 때문에 간단히만 정리
- Workflow Management Platform
- Open-source
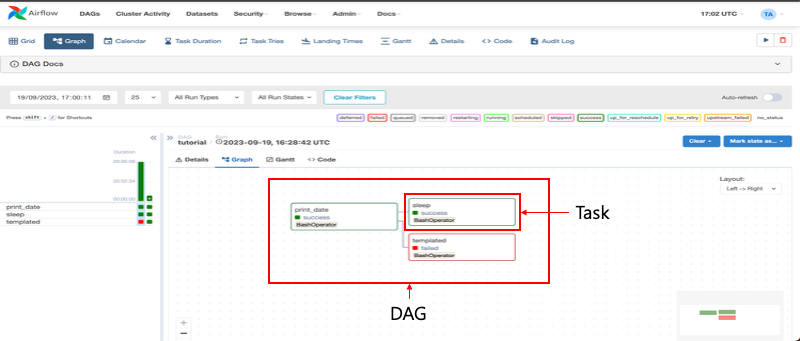
- DAG (Directed Acyclic Graph)
- 워크플로우를 정의하는 기본 단위
- 절대 무한 루프에 빠지지 않게 설계된 파이프라인 구조
- 여러 Task를 연결한 형태
- 단방향 실행 순서 (A -> B-> C)
- 무한 루프 X
- Python 코드로 생성
- DAG, Task, Operator, Sensor, Plugin, etc
- Web UI로 손쉽게 관리
- 배치 스케줄링, 메뉴얼 실행, Trigger
Amazon MWAA

A 작업 -> B 작업 -> 성공하면 뭐하고 실패하면 뭐하고
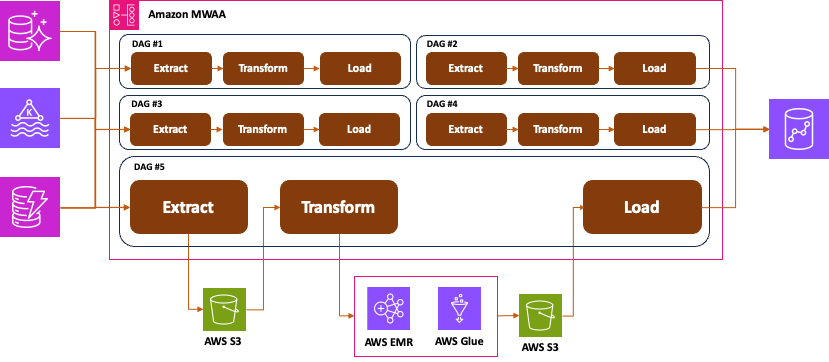
와 같은 데이터 작업을 코드로 짜서 스케줄링하는 Apache Airflow를 AWS가 대신 관리해주는 서비스
- Apache Airflow 서비스
- Amazon Managed Workflows for Apache Airflow
- 관리형 서비스
- 클릭으로 버전 선택 가능
- 워크플로우 코드
- S3에 저장됨
- DAG, Plugins, Requirements, etc
- 다양한 AWS 서비스와 통합
MWAA Architecture
- Meta Database: 파이프라인에서 사용하는 메타데이터 저장소
- Airflow Web Server: 웹 UI를통해 사용이 가능한 웹 서버
- Airflow Schedulers: DAG내 코드나 DAG 스케줄 등을 컨트롤하는 역할
- Airflow Worker(s): 스케줄러로부터 지시를 받아서 실제로 DAG 내 코드를 실행하는 역할

데이터 파이프라인에서의 MWAA
11-3. Kinesis 소개
지금까지의 작업이 데이터를 한 번에 모아서 뭉텅이로 처리하는 '배치(Batch) 처리'였다면,
Kinesis는 유저의 클릭 로그, 주식 호가, IoT 센서 데이터처럼 1초에도 수만 개씩 쏟아지는 '실시간 스트리밍 데이터'를 처리
하는 서비스이다.
Amazon Kinesis

- 실시간 데이터 스트리밍 서비스
- 데이터 스트리밍 수집, 처리, 분석
- 4가지 상세 서비스 제공
- Data Streams, Data Firehose, Data Analytics, Video Streams
- 실시간 데이터 파이프라인, 클릭스트림 분석
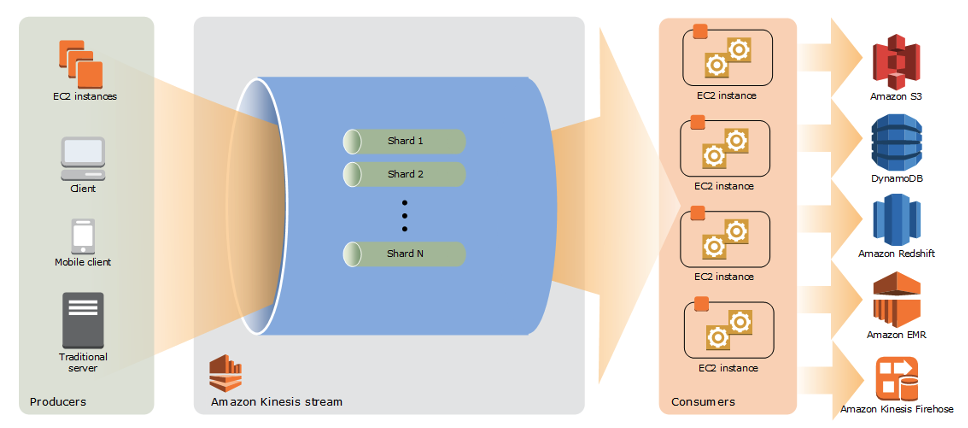
Kinesis Data Streams

- 실시간 스트리밍 데이터 수집 및 저장
- 샤드를 사용하여 확장 가능
- 데이터를 처리하는 애플리케이션을 만들어서 붙임
- 최대 365일 보존 가능
Kinesis Data Firehose

- 스트리밍 데이터를 다른 AWS 서비스로 전송
- 완전 관리형(무중단), 서버리스
- 별도의 코드 없이 동작
- 데이터 전송전 데이터 전환이 필요한 경우 보통 람다를 사용

Kinesis Data Analytics
- 스트리밍 데이터를 처리하고 분석
- 완전 관리형 서버리스
- SQL 또는 Apache Flink 애플리케이션 이용
- SQL 지원 종료 예정
- 2025.10.15 : 생성 불가능
- 2026.01.27 : 애플리케이션 삭제
- Apache Flink로 이관 필요
Kinesis Video Streams

- 실시간 비디오 스트리밍 데이터 수집 및 분석
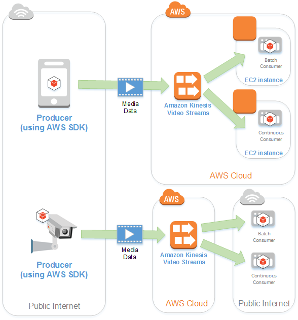
11-4. MSK 소개
Apache Kafka

- 오픈소스 대용량 분산 메시징 시스템
- 실시간 데이터 스트리밍 플랫폼
- 빠른 속도, 확장성, 스트리밍 처리, 내구성
- Kafka 구조
- Broker(서버 그자체, 메세지 저장 및 전송), Topic(메세지를 받고 보내는 주체),
Producer(데이터를 보내는 역할), Consumer(데이터를 읽는 역할)
- Broker(서버 그자체, 메세지 저장 및 전송), Topic(메세지를 받고 보내는 주체),
- Kafka 확장 서비스
- Kakfa Connect(외부 시스템 간에 이동을 자동화),
Kakfa Streams(실시간으로 계산, 집계, 변화 하는 프레임워크),
Schema Registry(Kafka의 메세지 데이터의 스키마 구조를 관리하는 프레임워크)
- Kakfa Connect(외부 시스템 간에 이동을 자동화),
- MSA, 로그 수집, 실시간 분석, 데이터 파이프라인
Apache Kafka Architecture

Amazon MSK

- Managed Streaming for Apache Kafka
- Kafka 클러스터 운영, 및 유지
- 완전 관리형, 확장성, 보안, 모니터링
- Kafka 지식 필요
Kinesis vs MSK
| Kinesis | d | |
| 유형 | AWS 완전 관리형 스트리밍 서비스 | Apache Kafka를 관리형으로 제공 |
| 진입장벽 | 쉬움 | Kafka 지식 필요 |
| 생태계 | AWS 중심 | Kafka 생태계 |
| 커스터마이징 | 제한적 | 매우 유연 |
| 클라이언트 언어 | AWS SDK / Kinesis API | Kafka 클라이언트 라이브러리 |
| 메시지 유지 기간 | 최대 365일 | 무제한 |
| 확장성 | 매우 뛰어남 | 뛰어나지만 고려할 요소 (파티션 등) 존재 |
'DataEngineer(DE) > AWS를 이용한 데이터 엔지니어링' 카테고리의 다른 글
| AWS를 이용한 데이터 엔지니어링(11) - 부동산 API를 활용한 데이터 파이프라인 구축 (0) | 2026.04.08 |
|---|---|
| AWS를 이용한 데이터 엔지니어링(9) - QuickSight (0) | 2026.04.03 |
| AWS를 이용한 데이터 엔지니어링(8) - Redshift & 최적화 전략 (1) | 2026.04.02 |
| AWS를 이용한 데이터 엔지니어링(7) - Lambda (0) | 2026.03.31 |
| AWS를 이용한 데이터 엔지니어링(6) - Athena & Athena 최적화 전략 (0) | 2026.03.30 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- Prodcuder DAG
- kafka
- lake house
- airflow
- Data Pipeline
- AWS Glue Catalog
- lakehouse
- Consumer DAG
- DataSet
- DAG
- 데이터파이프라인
- s3
- Data engineering
- Unity Catalog
- RDD
- elasticip
- catchup
- Glue ETL
- docker
- Data Engineerring
- spark
- Daynamic Task
- de
- AWS
- Glue
- Databricks
- Spark structured streaming
- Backfill
- iceberg
- Data Dngineering
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
글 보관함