

티스토리 뷰
AWS를 이용한 데이터 엔지니어링(6) - Athena & Athena 최적화 전략
코딩하는 제리코 2026. 3. 30. 19:187-1. Athena 소개

Athena
S3에 있는 파일을 DB처럼 SQL로 조회할 수 있게 해주는 서버리스 서비스
- 표준 SQL을 사용하는 대화형 분산 쿼리 서비스
- Presto 쿼리 엔진(분산 처리 가능, 대용량 데이터 효율적 조회 가능)
- "큰 데이터를 여러 컴퓨터로 나눠서 처리"
- S3에 저장된 데이터를 분석
- SCV, JSON, ORC, Avro, Parquet
- Serverless
- Glue Data Catalog와 통합
- 로그 분석, Ad-hoc분석, BI 도구 통합
- 가격 - S3 데이터 스캔 비용 ($5/TB)
# S3 전체를 읽어서 요금이 폭발하는 예시
SELECT * FROM logs;
# 일부만 읽어서 요금을 절약하는 예시
SELECT * FROM logs WHERE date = '2026-03-28';
Athena 에서 지원하는 Data File Formats
- 기본 형
- 한 줄 씩 읽기 때문에 필요 없는 칼럼도 읽음
- CSV, TSV
- JSON
- Apache Web Logs
- Columnar Formats
- 칼럼 단위로 저장되기 때문에 필요한 칼럼만 읽을 수 있음
- Parquet
- ORC
테이블 생성
S3와 같은 데이터 저장소는 DB가 아니기 때문에 SQL을 사용할 수 있도록 DDL을 통해 테이블을 만들게 된다.
1. DDL을 이용하여 생성
CREATE TABLE logs (
user_id string,
event string
)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe' -- '이 파일에 있는 데이터는 JSON 형태다. (만약 형태가 바뀌면 이 내용도 바뀜)'
LOCATION
's3://bucket/logs/';
2. Glue Data Catalog / Crawler를 이용한 생성
- 자동으로 파일 읽고 스키마 생성
7-2. Athena 성능 향상 전략
앞에서 말했듯이 Athena는 읽은 만큼 돈을 내기 때문에 성능 전략이 필요함
데이터 파티셔닝
- 데이터를 분할 저장하여 일부 데이터만 검색
- Athena 에서 데이터 파티셔닝을 하기 위한 세가지 단계
- S3에는 파티셔닝 구조로 설정
- DDL로 파티셔닝 설정
- 메타데이터 스토어에 파티션 등록
- 자동 or 수동으로 매핑
데이터 파티셔닝 - 자동 매핑
- S3
- 파티션 키 명시
- s3://<버킷 명>/<prefix 값>/파티션 키 = 값/<객체 명>
- DDL
- 파티션 키와 데이터 타입 지정
- PARTITIONED BY 구문 이용
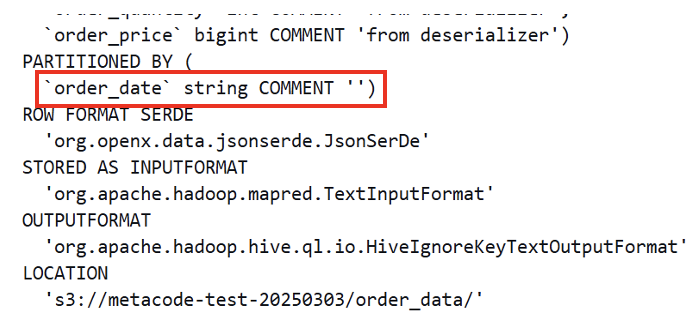
PARTITIONED BY (date string)
- 파티션 등록
- MSCK REPAIR 구문을 이용한 등록
MSCK REPAIR TABLE logs;

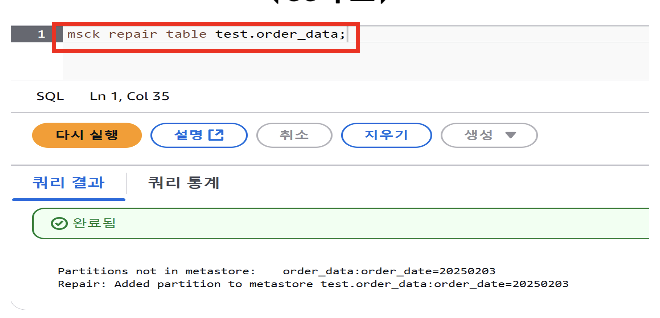
데이터 파티셔닝 - 수동 매핑
- S3
- 파티션 키 명시 X
- s3://<버킷 명>/<prefix 값>/파티션 값/<객체 명>
- DDL
- 파티션 키와 데이터 타입 지정
- PARTITIONED BY 구문 이용
- 파티션 등록
- ALTER TABLE ~ ADD PARTITION 구문을 이용한 등록
ALTER TABLE test.order_data_manual_mapping ADD PARTITION (order_date='20250202') LOCATION 's3://athena-test/order_data_manual_mapping/20250202/';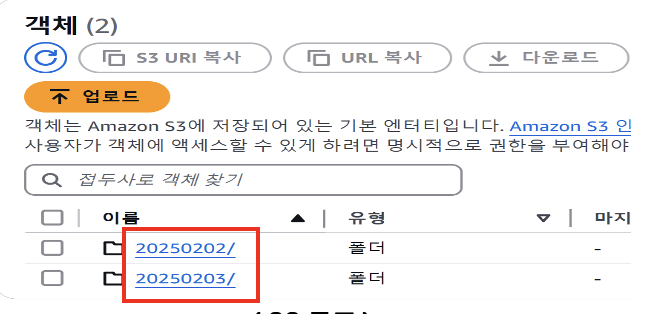

파티션 프로젝션 (Partition Projection)
파티션이 많아지면 Glue 메타데이터 관리 비용이 증가 하고 성능이 느려지므로 필요함
- 파티셔닝 자동화
특징
- 설정 방식 (DDL에서 TBLPROPERTIES 사용)
- 자동 파티션 추론
- 유지 관리 용이성
제약 조건
- Glue 또는 Hive의 파티션 메타데이터를 무시함
- 정의된 범위를 벗어난 값에 대해 오류 반환 X
- 예시: 달(month)에 대한 파티션 값의 범위(range)를 int형으로 1~12로 설정해두었다면 만약 13이라는 데이터가 들어오게 되면해당 데이터가 무시되게 됨
- Athena를 통해 쿼리할 때만 사용 가능함
- S3 구조는 파티션 구조로 설정 (자동 매핑, 수동 매핑 상관 없음)
- DDL 작성 시 TBLPROPERTIES 설정
파티션 projection에서는 파티션값을 메타데이터 스토어에 저장하지 않고 추론하기 때문에
show partitions 구문을 통한 출력 값에는 아무 값도 안 보이게 됨.
따라서 projection에는 msck 나 alter table과 같은 구문도 필요없게 되는 것임.
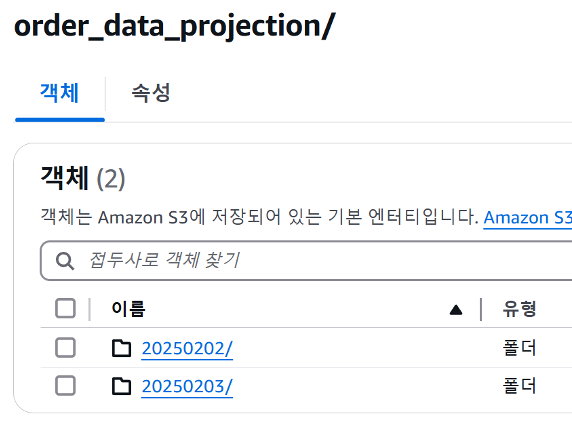

실제 partition projection이 효과가 있는가 확인
select * from test.order_data_without_partition우선 partition 이 안되어 있는 S3 데이터를 아래와 같이 읽어 왔을때 전체 스캔 데이터가 0.85KB 로 나오고 전체 결과인 8개가 나오게 된다.
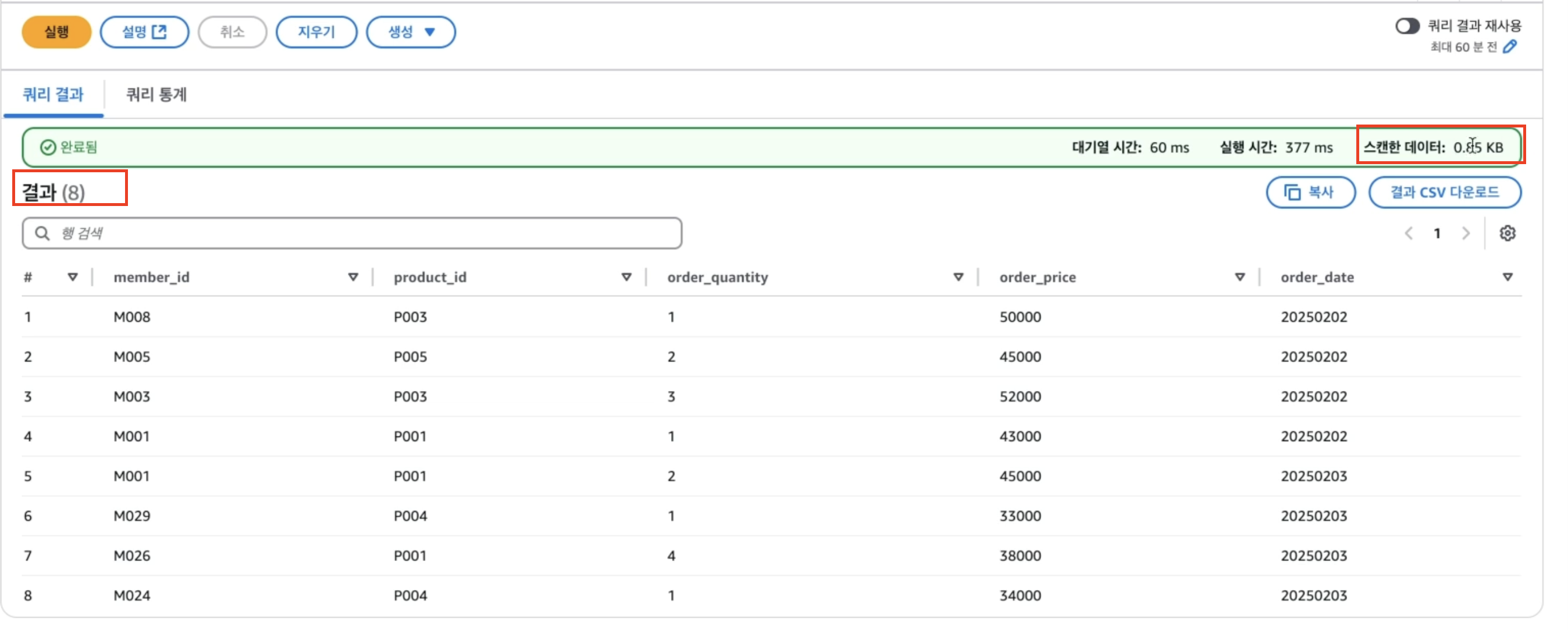
다만 이제 where 구문을 통해 order_date가 20250202 인 것만을 걸러서 쿼리해봐도 여전히 0.85KB와 결과 8개가 나오게 된다.
즉, 풀스캔을 하고 있다는 의미이다.
이제 partition이 있는 테이블에다가 동일하게 쿼리해보면,
결과는 반으로 줄고 스캔한 데이터 양도 준것을 확인할 수 있다.

압축 & Columnar (비용 최적화 핵심)
Athena는 읽은 데이터 기준 과금이기 때문에 압축하는것이다.
- Columnar 포맷 및 데이터 압축
- 사전에 S3에 데이터를 압축 후 저장
- 데이터 스캔 양이 줄어들어 비용 절감
- Parquet, ORC와 같은 Columnar 포맷 이용
- DDL에서 STORED AS 구문 이용
- BZIPS, GZIP, LZ4, SNAPPY 등 다양하게 지원
- DDL에서 설정
아래는 parquet 포맷을 이용하였을때의 DDL내용이다.
-- 테이블 생성 쿼리
CREATE EXTERNAL TABLE test.order_data_parquet_compression (
member_id string,
product_id string,
order_quantity int,
order_price int
)
PARTITIONED BY (
order_date string
)
STORED AS PARQUET
LOCATION
's3://athena-test/order_data_parquet_compression/'
TBLPROPERTIES (
'parquet.compression'='SNAPPY'
)
;7-3. Athena + Glue
조직의 규모가 크고 데이터가 크면 주로 사용하는 강력한 조합

- 메타데이터 중앙화
- 자동 스키마 관리
- ETL을 이용한 데이터 변환
- 메타데이터 + 쿼리 분석
- 대용량 데이터를 다룰 때 좋음
Raw Data → S3
↓
Glue ETL (정제)
↓
Parquet 저장
↓
Glue Catalog
↓
Athena 조회
1) Glue의 Data Catalog을 사용하는 아키텍쳐
Glue의 Crawler를 통해서 자동으로 S3 데이터를 스캔해서 테이블과 스키마를 생성하고 파티션도 자동으로 관리할 수 있다.
이렇게 되면 사용자는 이제 Athena에 서 데이터의 스키마나 테이블,
파티션에 신경 쓰지 않고 분석에만 신경을 쓸 수 있다.

2) Glue ETL도 함께 사용하는 아키텍쳐
데이터 규모가 커져서 기존의 ETL 툴로는 대응이 힘들때 사용하면 좋다.
또한, Glue ETL을 통해 데이터를 Parquet나 ORC와 같은 Columnar 데이터로 변환하면,
Athena에서 쿼리 비용과 성능을 최적화 할 수 도 있다.

등등,, 다양한 아키텍쳐들이 있으니 천천히 하나하나 공부하는 것도 좋을것 같다.
단, 단순히 아키텍쳐를 외운다기보단 왜 이러한 아키텍쳐를 사용하는가,
서비스의 어떤 장점을 활용하고 단점을 보완한 아키텍쳐인가를 고민해보면 좋을 것 같다.
'DataEngineer(DE) > AWS를 이용한 데이터 엔지니어링' 카테고리의 다른 글
| AWS를 이용한 데이터 엔지니어링(8) - Redshift & 최적화 전략 (1) | 2026.04.02 |
|---|---|
| AWS를 이용한 데이터 엔지니어링(7) - Lambda (0) | 2026.03.31 |
| AWS를 이용한 데이터 엔지니어링(5) - Glue, Data Catalog, Glue ETL (0) | 2026.03.28 |
| AWS를 이용한 데이터 엔지니어링(4) - 스토리지 & 데이터 레이크 & 레이크 하우스 (0) | 2026.03.27 |
| AWS를 이용한 데이터 엔지니어링(3) - EC2 & EBS & ElasticIP & Security Group (0) | 2026.03.26 |
- Total
- Today
- Yesterday
- Prodcuder DAG
- s3
- lakehouse
- iceberg
- Spark structured streaming
- Daynamic Task
- spark
- Backfill
- lake house
- airflow
- Glue
- docker
- DAG
- Data Dngineering
- DataSet
- catchup
- RDD
- Data Pipeline
- Consumer DAG
- Databricks
- kafka
- de
- Data engineering
- Glue ETL
- elasticip
- 데이터파이프라인
- AWS
- Data Engineerring
- AWS Glue Catalog
- Unity Catalog
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |