

티스토리 뷰
데이터 엔지니어링 환경에서 Spark를 본격적으로 다루기에 앞서,
그 근간이 되는 '빅데이터'의 개념과 기존 방식의 한계를 극복한 'Spark'의 탄생 배경 및 아키텍처를 정리한다.
1. 빅데이터(Big Data)의 이해
- 데이터 양의 폭발적 증가: 매일 생성되는 데이터의 절대적인 규모가 과거와 비교할 수 없을 만큼 커졌다.
- 기존 데이터 처리 방식의 한계: 단일 서버나 전통적인 데이터베이스로는 이 거대한 데이터를 감당할 수 없게 되었다.
- 비정형 데이터의 등장: 텍스트, 이미지, 비디오 등 다양한 형태를 포함하는 비정형 데이터가 폭증하면서,
기존 관계형 데이터베이스(RDB)에서 처리하기 어려운 특성을 띠게 되었다.

1-1. 데이터 저장소: Data Warehouse vs Data Lake
대용량 데이터를 저장하는 방식은 크게 두 가지로 나뉜다.
- Data Warehouse (데이터 웨어하우스): 사용자의 의사 결정에 도움을 주기 위하여 다양한 소스로부터 축적된 데이터를 '공통의 형식으로 변환'해서 관리하는 중앙 데이터베이스다.
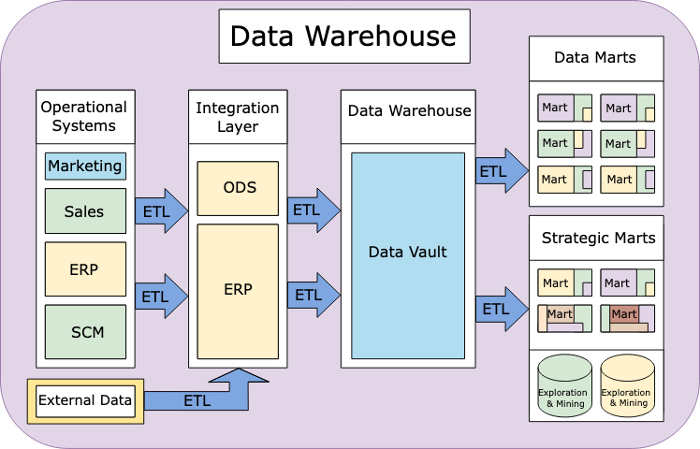
- Data Lake (데이터 레이크): 대량의 정형, 반정형, 비정형 데이터를 저장, 처리, 보호하기 위한 중앙 집중식 저장소다.
크기 제한을 무시하며, 가공되지 않은 'Raw Data' 형태로 바로 저장할 수 있다는 장점이 있다.- 따라서 데이터를 사용하는 측에서 데이터를 가공해서 원하는 형식대로 쓴다.

위 사진에서 Data Warehouse는 공통된 형식을 제공하지만,
Data Lake를 보면, Raw Data에서 공통된 형식을 주도록 별도로 Data Warehouse를 만들어서 BI 도구들로 사용하기도하고
바로 Raw Data에서 가져가서 사용하기도 한다. (Data Science 나 머신 러닝)
Data Lakehouse는 이러한 별도의 Warehouse를 만들지 않고,
내부에서 ETL까지 통합적으로 제공하는 개념이다. (뒤에서 공부할 Data Bricks 도 해당 레이크하우스)
1-2. 하둡(Hadoop)의 등장
이러한 빅데이터를 처리하기 위해 등장한 것이 바로 Apache Hadoop이다.
하둡은 MapReduce 프로그래밍 모델을 사용하여,
여러 대의 컴퓨터(클러스터)에서 대규모 데이터 세트를 분산 저장 및 처리할 수 있도록 돕는 오픈소스 프레임워크다.

1-3. 하둡의 컴포넌트
- HDFS (Hadoop Distributed File System): Java 기반의 분산 파일 시스템이다.
NameNode와 DataNode(실제로 데이터를 저장하는 노드)로 구성되며,
서버를 늘려 용량을 확장하는 수평적 확장(Horizontal Scaling)을 지원한다.
로컬 파일 시스템 4개를 연결하면 40TB를 쓸 수 있는건 이해가 됐다.
"근데 그냥 처음부터 40TB 짜리 슈퍼 컴퓨터 하나를 두면 되는거 아닌가?"
그럴수도 있겠지만,
로컬 파일 시스템 10TB 가 훨씬 가격적으로 저렴하고,
중간중간 용량이 부족할때 만약 슈퍼 컴퓨터를 사용하면 값비싼 슈퍼 컴퓨터 한대를 증설해야하지만,
하둡의 수평적 확장을 사용하면 로컬 파일 시스템 하나만 추가하면 됨으로써 더 간편하고 저렴하다.

- YARN (Yet Another Resource Negotiator): 워크로드 관리, 모니터링, 보안 관리, 클러스터에 작업 할당 등 하둡의 전반적인 리소스를 관리한다. (Resource Manager, Node Manager, Application Master 로 구성됨)
- MapReduce: 하둡 에코시스템의 핵심인 Java 기반 분산 처리 프레임워크다.
분산 처리의 복잡성을 없애주며 다음 3단계로 동작한다.- Map: 분할한 작은 데이터 블록에 함수를 적용하고, 결과(Key-Value)를 임시 스토리지에 저장한다.
- Shuffle: 같은 키에 속하는 결과물이 같은 노드로 모이도록 위치를 재배정한다.
- Reduce: 동일 키에 대한 값을 최종적으로 집계한다.
- Hadoop Common: 하둡 모듈들을 실행하기 위한 공통 유틸리티 집합이다.
1-3. Spark VS Hadoop
- Apache Spark는 Hadoop의 한계를 극복하기 위해 개발된 분산 데이터 처리 프레임워크
- 인메모리 처리를 통해 성능 크게 향상
- 위에서 하둡은 MapReduce 를 통해서 분산 처리를 돕는데,
이때 Map을 통해 Key-Value를 임시 스토리지에 저장할때 디스크 I/O 가 발생하는데
이 I/O 알다시피 매우 값비싼 연산이라 성능이 크게 저하되었던 것이다.
- 위에서 하둡은 MapReduce 를 통해서 분산 처리를 돕는데,

Spark를 사용하는 방법은 위 첫번째 사진처럼 크게 3가지가 있다.
- Standalone: 이미 하둡에 HDFS가 잘 구현되어 있기 때문에 하둡의 HDFS와 함께 사용하는 유형
- Over Yarn: Spark에는 리소스 관리가 없기에 하둡의 Yarn도 함께 사용하는 유형
- Spark in MR(SIMR): 기존 하둡의 MR(Map Reduce)와 함께 사용하는 유형
2. Spark의 이해와 아키텍처
대규모 분산 데이터 처리에 최적화 된 도구 (하둡은 저장과 처리에 했던것과 차별점)
대규모 데이터 처리의 중요도가 올라가고 있는만큼
데이터 프로세싱을 분산 처리 하는 기술이 필수적인 요소가 되어 가고 있다.
Apache Spark는 하둡 MapReduce의 태생적 한계와 단점을 극복하기 위해 개발된 분산 데이터 처리 프레임워크다.
2009년 UC 버클리 AMP Lab에서 프로젝트로 시작되어, 2013년 Apache 최상위 프로젝트로 승격되었다.
2-1. 왜 Spark를 사용하는가? (장점)
- 메모리 기반의 빠른 처리: 디스크 입출력을 반복하던 하둡과 달리, 인메모리(In-memory) 처리를 통해 성능을 크게 향상시켰다.
- 쉬운 구현: 복잡한 MapReduce 코드 대비 훨씬 직관적이고 쉬운 API를 제공한다.
- 다양한 라이브러리: MLLib(머신러닝), GraphX(그래프 처리), Streaming 등 강력한 내장 라이브러리를 지원한다.
- 범용성: 특정 환경에 종속되지 않고 다양한 클러스터 환경 및 데이터 소스와 유연하게 연동된다.


2-2. Spark의 아키텍처와 작동 원리


Spark의 클러스터 구조는 크게 세 가지 핵심 요소로 나뉜다.
- Driver (Spark Context): 백그라운드 프로세스와 정보들을 관리하는 두뇌 역할을 한다.
Cluster Manager의 종류(YARN, k8s 등)에 상관없이 일관되게 동작한다. - Executor: Scheduler로부터 실제 Task를 할당받아 연산을 실행하는 워커(Worker) 역할이다.
- Cluster Manager: 클러스터 내 Node 상태를 체크해서 작업을 분배하고, 죽은 Node를 제외하는 등의 기능을 수행한다.
주의할 점은 Spark 자체는 Cluster Manager 역할을 하지 않는다는 점이다.
대신 YARN, Mesos, Kubernetes(k8s) 등 이미 잘 구현된 외부 클러스터 매니저를 가져다 쓴다.
참고1) - Driver (Spark Context)
Spark Task를 실행하기 위해서는 반드시 환경을 초기화(Initialize Environment)해주는 Spark Context를 가장 먼저 생성해야 한다.
그리고 Spark 어플리케이션은 처음실행될때 Spark Context가 떠야지만 프로그램이 실행될 수 있다.
그래서 Spark Context를 생성하는 부분을 별도의 공유 함수로 작성해두는것도 좋은 방법이다.
참고2) - 추후 실습으로 확인 해볼 예정
에러가 발생했을때 이 에러가 Driver와 Executor 중 어디서 발생했는지 확인을 해야하고
메모리가 부족했을때도 둘 중 어디의 메모리가 부족한지를 개별적으로 봐야한다.
2-3. PySpark vs Scala
Spark는 Scala, Java, Python, R 등 다양한 언어를 지원한다.
데이터 엔지니어링 실무에서는 주로 Python 기반의 PySpark가 널리 쓰이지만, (이번 포스팅에서는 파이썬으로 할 예정)
다음과 같은 특수한 상황에서는 네이티브 언어인 Scala를 사용하는 것이 권장된다.
- 가장 최신의 Spark API 기능이 즉각적으로 필요할 때
- 코어 단위의 세밀한 커스터마이징이 필요할 때
- 극한의 성능 최적화가 요구될 때
- Spark 내부 구조 분석 및 깊은 수준의 디버깅이 필요할 때
2-4. Databricks (데이터브릭스)
빅데이터 플랫폼 중에 데이터 레이크 하우스를 만드는 플랫폼
Spark를 클라우드 플랫폼에서 실행 할 수 있도록 도와준다.
최근 실무에서는 Spark를 클라우드 환경에서 완벽하게 관리해 주는
Databricks(https://www.databricks.com/) 플랫폼을 많이 채택한다.
- 클라우드 플랫폼 위에서 동작하는 최적화된 Spark(Spark on Cloud Platform)를 제공한다.
- 복잡한 Cluster Management를 자동으로 해결해 준다.
- 편리한 Notebook 및 Workspace 환경을 제공하여 협업을 돕는다.
- Database와 Catalog 기능을 내장하여 통합적인 데이터 관리가 가능하다.
- Optimized Spark를 사용할 수 있다.
'DataEngineer(DE) > Spark- 데이터 처리, 최적화' 카테고리의 다른 글
| Spark (4) - Spark의 데이터 종류 및 처리법 - DataFrame & Dataset 편 (2) | 2026.04.16 |
|---|---|
| Spark (4) - Spark의 데이터 종류 및 처리법 - RDD 편 (0) | 2026.04.15 |
| Spark (3) - 첫 번째 Spark 애플리케이션 : Word Count로 이해하는 분산 처리 (1) | 2026.04.14 |
| Spark (2) - Spark 구성 요소 이해하기 - Databricks & Unity Catalog & RDD (1) | 2026.04.14 |
| Spark (0) - 학습 목표 설정 (0) | 2026.04.13 |
- Total
- Today
- Yesterday
- de
- Spark structured streaming
- lakehouse
- Data Dngineering
- DataSet
- lake house
- kafka
- s3
- airflow
- Prodcuder DAG
- Unity Catalog
- catchup
- Databricks
- spark
- AWS
- Glue
- Data engineering
- Data Engineerring
- iceberg
- elasticip
- 데이터파이프라인
- Consumer DAG
- RDD
- Glue ETL
- Daynamic Task
- Data Pipeline
- DAG
- docker
- AWS Glue Catalog
- Backfill
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |