

티스토리 뷰
DataEngineer(DE)/Airflow 3.0 & DAG 개발 및 최적화
Airflow 3.0과 DAG 개발 및 최적화 (8) - AWS Data Pipeline & Capstone 프로젝트
코딩하는 제리코 2026. 4. 13. 12:00Airflow 3.0 강의의 마지막 차시에서는 실무에서 가장 많이 쓰이는 AWS 기반의 ETL 파이프라인 구축과 운영의 핵심인 Backfill 전략, 그리고 이를 집대성한 Capstone 프로젝트를 다룬다.
1. ETL 개념 정리 및 분리 전략
1-1 . ETL 단계별 정의
데이터 파이프라인의 핵심 구성 요소인 ETL은 다음과 같이 정의한다.
- Extract (추출): 원천 데이터를 소스 시스템에서 추출하는 단계다.
- Transform (변환): 추출된 데이터를 정제, 가공하여 분석 가능한 형태로 변환한다.
- Load (적재): 변환된 데이터를 DW(Data Warehouse)나 Data Lake에 적재한다.
- 통합 과정: 위 세 단계가 유기적으로 연결되어 데이터 프로덕트의 기반을 형성한다.
1-2. ETL 단계 분리의 중요성
각 단계를 명확히 분리함으로써 유지보수성과 확장성을 향상시킨다.
- 유지보수성: 단계별 최적화가 가능하며, 장애 발생 시 원인 파악 및 해결이 용이하다.
- 확장성: Extract는 소스 연결에, Transform은 로직과 품질에, Load는 적재 성능에 집중할 수 있다.
- 장애 대응: 특정 단계에서 문제가 생겨도 해당 단계만 재실행하여 복구 시간을 단축한다.
2. ETL 단계별 상세 특징
2-1. Extract (추출)
- 데이터 소스 연결: S3 등 Object Storage에서 효율적으로 데이터를 읽어온다.
- 구조 설계: 파일 및 폴더 구조 설계가 전체 파이프라인의 성능과 유지보수성에 직결된다.
- 원본 보존: 원본 데이터 보존 전략을 통해 언제든 재처리가 가능하도록 가용성을 확보한다.
2-2. Transform (변환)
- 프로세스: Cleaning(결측값 처리), Normalizing(표준화/정규화), Enriching(파생변수 생성) 과정을 거친다.
- 도구 활용: Python/Pandas로 효율적으로 처리하며, 경량 변환은 Lambda, 대용량 처리는 Glue를 활용하는 것이 적합하다.
2-3. Load (적재)
- Redshift: COPY 명령어를 사용하여 S3에서 직접 대용량 데이터를 병렬로 적재한다.
- Athena: CTAS(Create Table As Select) 문을 통해 새 테이블을 생성하고 관리한다.
- Partition 설계: 날짜나 카테고리별로 파티션을 설계하는 것이 쿼리 성능 최적화의 핵심이다.
3. 운영 및 안정성 체크리스트
3-1. 운영 체크리스트
- DAG 스케줄: 워크플로우 실행 주기와 시간이 정확한지 확인한다.
- 스키마 변경: 소스 데이터의 구조 변화를 감지하고 대응하는 체계를 갖춘다.
- 데이터 누락: 예상 레코드 수와 실제 처리된 데이터 수를 비교 검증한다.
- SLA 준수: 약속된 시간 내에 데이터 제공이 완료되는지 모니터링한다.
- 로그 품질: 문제 원인 추적이 용이하도록 상세한 로그를 기록한다.
3-2. 품질 및 안정성 체크포인트
- Idempotent (멱등성): 동일한 입력에 대해 항상 같은 결과를 보장하며, 중복 실행 시에도 데이터 일관성을 유지한다.
- Partition: 덮어쓰기(Overwrite) 정책을 명확히 정의하고 파티션 단위로 관리한다.
- 실패 Task: 재시도 횟수와 간격을 설정하고, 특정 Task만 선택적 재실행이 가능하도록 구성한다.
- 모니터링: Slack/이메일 알림과 대시보드를 통해 파이프라인 상태를 시각화한다.
4. Backfill (재처리) 전략
Backfill 없는 파이프라인은 반쪽짜리 파이프라인이라고 해도 무방할 정도로 중요한 개념이다.
Backfill은 앞선 포스팅에서도 설명했지만, '얼마나 쉽게 되돌릴 수 있는가' 와 같은 개념이다.
4-1. 개념 및 필요성
- 정의: 과거 데이터를 다시 처리하는 작업으로, 데이터 파이프라인 운영의 필수 기능이다.
- 필요 시점: 데이터 누락, 로직 오류 발견, 스키마 변경, 시스템 초기 구축 시 과거 데이터 일괄 적재가 필요한 경우 활용한다.
4-2. 설계 원칙 및 운영
- Idempotent 설계: 여러 번 실행해도 결과가 같도록 하여 중복 처리를 방지한다.(멱등성)
- Partition 기반: 특정 기간만 선택적으로 재처리할 수 있는 구조를 갖춘다.
- 검증 로직: Backfill 전후의 데이터 정합성을 검증하여 안정적인 재처리를 보장한다.
- 생산성: 단일 명령으로 다중 날짜 처리가 가능하도록 설계하여 운영 효율을 높인다.
5. 실습 및 Capstone 프로젝트 리뷰
● 실습 코드 관련
이번 실습은 DAG 포스팅에서 단계별로 배운 내용을 종합해서 하나의 파이프라인을 만드는 실습이라,
중복되는 개별 DAG 코드라서 DAG 별 코드 첨부를 하지 않고 설명도 생략하였다.
자세한 개별 DAG 코드들에 대한 정리는 포스팅별로 자세히 설명되어 있으니 참고바란다.
(예시: http://2026.04.09 - [DataEngineer(DE)/Airflow 3.0 & DAG 개발 및 최적화] - Airflow 3.0과 DAG 개발 및 최적화 (4) - DAG 실행 제어 & Backfill )
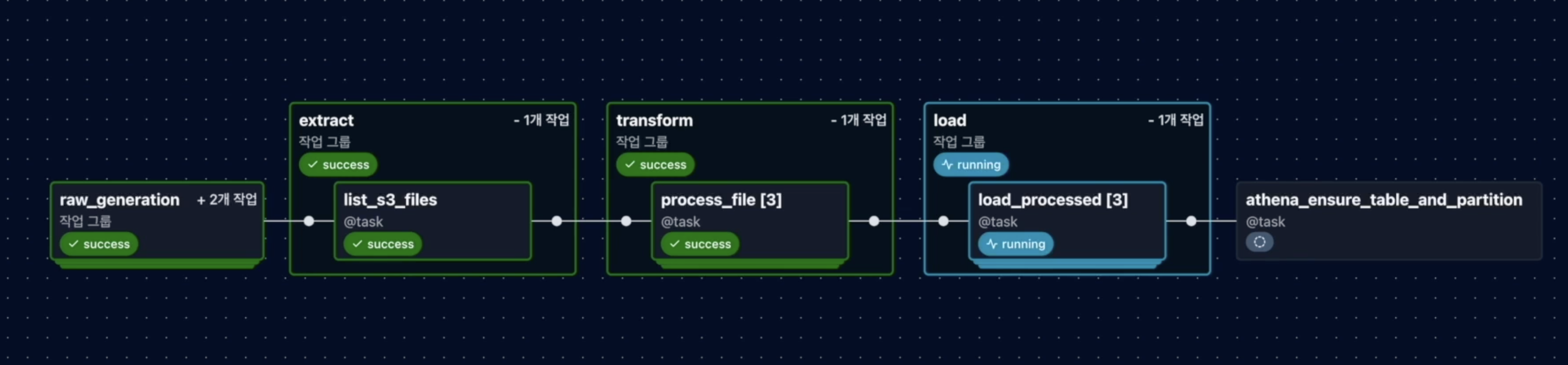
5-1. AWS 기반 ETL 파이프라인 구성

기존의 복잡한 방식을 TaskFlow API 기반으로 개선하여 코드를 간소화했다.
- Extract: S3 Raw 폴더 목록 조회 및 데이터 로드.
- Transform: JSON/CSV 가공, 데이터 타입 변환 및 비즈니스 룰 적용.
- Load: Redshift COPY 명령 실행 및 Athena 테이블 갱신.
웹 UI 그리드 뷰로 구조를 보자면 아래와 같다.
5-2. Dataset 기반 DAG 연계
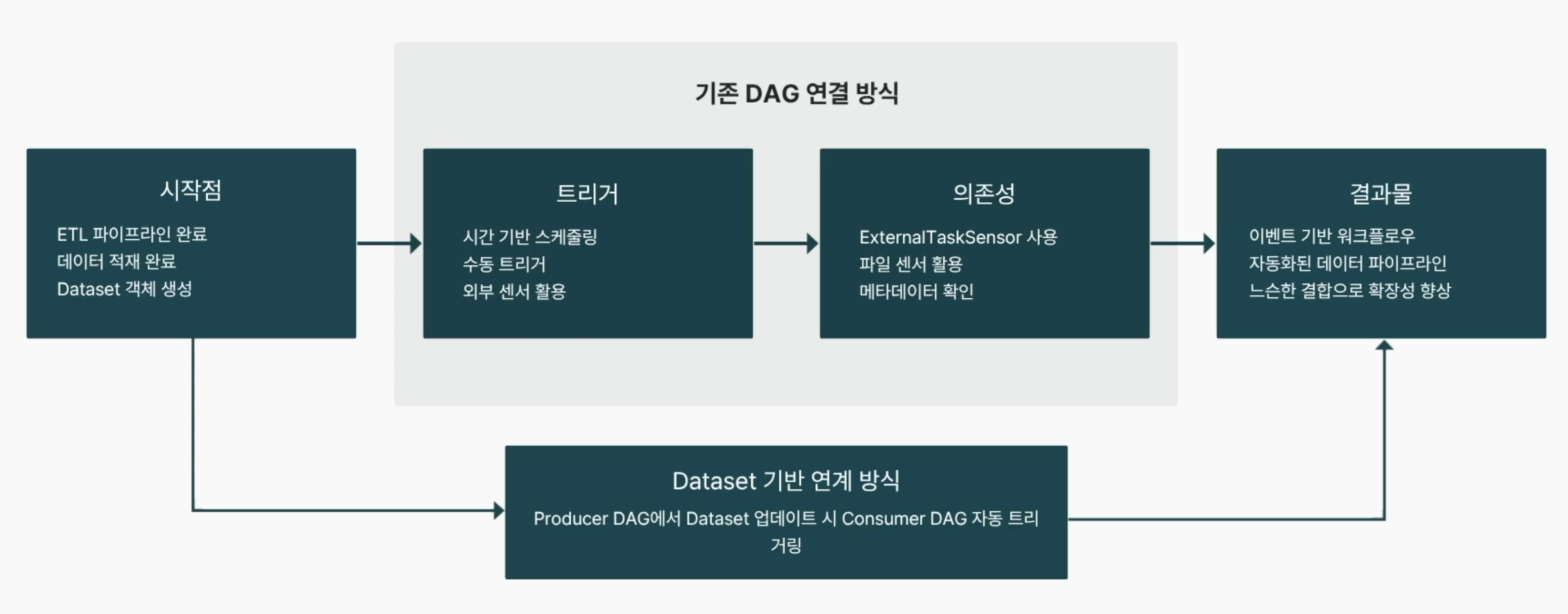
기존의 시간 기반 스케줄링이나 Sensor 방식에서 벗어나 Dataset 기반으로 전환했다.
- Producer:
- S3 데이터 수집 및 적재
- 데이터 변환 및 처리
- Redshift/Athena 적재
- Dataset 객체 업데이트 및 이벤트 발생
- Consumer:
- Dataset 업데이트 감지
- 메트릭 검증 및 품질 확인
- 비즈니스 로직 후처리
- 리포트 생성 및 알림 전송
- 장점: 느슨한 결합(Loose Coupling)을 통해 파이프라인의 확장성이 향상된다.
5-3. Capstone Backfill 시뮬레이션
- 특정 날짜의 누락 데이터를 식별하고 재처리하는 과정을 실습했다.
- 시작일과 종료일을 지정하여 대규모 데이터를 병렬로 처리하는 리소스 관리 방법을 학습했다.
- 실패한 Task의 원인을 분석하고 운영 환경에서의 복구 능력을 검증했다.
6. 마무리 및 소감
S3에서 데이터를 추출하고 Airflow로 변환 후 Redshift와 Athena에 적재하는 전체 파이프라인을 구축해보았다.
또한 Dataset 기반 후처리까지 하는 등 비교적 완전한 ETL을 구축해보았다.
또한 운영 관점에서 Backfill 시뮬레이션을 통해 실제 운영 환경에서 발생할 수 있는 시나리오를 경험하고 개응 방법을 간단하게라고 학습할 수 있었다.
이번 학습 내용을 바탕으로 실무에서는 더욱 견고한 데이터 엔지니어링 환경을 구축할 수 있으면 좋겠다.
'DataEngineer(DE) > Airflow 3.0 & DAG 개발 및 최적화' 카테고리의 다른 글
| Airflow 3.0과 DAG 개발 및 최적화 (7) - Dataset 기반 파이프라인 (0) | 2026.04.11 |
|---|---|
| Airflow 3.0과 DAG 개발 및 최적화 (6) - DAG 구조화 전략 & Dynamic Task Mapping (0) | 2026.04.11 |
| Airflow 3.0과 DAG 개발 및 최적화 (5) - Airflow 3.0 - XCom & Variable - AWS (0) | 2026.04.10 |
| Airflow 3.0과 DAG 개발 및 최적화 (4) - DAG 실행 제어 & Backfill (0) | 2026.04.09 |
| Airflow 3.0과 DAG 개발 및 최적화 (3) - First DAG-TaskFlow API (0) | 2026.04.09 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- lakehouse
- lake house
- catchup
- DAG
- DataSet
- de
- spark
- 데이터파이프라인
- airflow
- Data Pipeline
- iceberg
- Backfill
- Glue
- Spark structured streaming
- kafka
- docker
- Data Engineerring
- Unity Catalog
- RDD
- Consumer DAG
- elasticip
- s3
- Data engineering
- AWS
- Prodcuder DAG
- Daynamic Task
- AWS Glue Catalog
- Data Dngineering
- Databricks
- Glue ETL
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
글 보관함