

티스토리 뷰
DataEngineer(DE)/Airflow 3.0 & DAG 개발 및 최적화
Airflow 3.0과 DAG 개발 및 최적화 (2) - Airflow 3.0 Architecture & Docker
코딩하는 제리코 2026. 4. 9. 16:300. 강의 목차
1. Airflow 3.0 Architecture 핵심: 역할 분리 철학, 전체 학습 로드맵
2. DAG Parsing, Execution: "언제 읽히고, 언제 실행 되는가?"
3. 왜 Docker로 Airflow를 실행하는가?: 실무 관점에서 Docker를 써야 하는 이유
4. Docker & Docker Compose 설치: 개발 환경 구성
5. Airflow 3.0 Docker Compose 실행: Airflow Docker 컨테이너들 띄우기
6. Web UI 접속 & Scheduler 로그 확인: Web UI 구조, Scheduler 로그로 실행 흐름추적
Airflow 3.0 Architecture 핵심
1-1. Control Plane & Execution Plane (역할 분리)
Airflow 3.0 아키텍처는 크게 판단/통계를 담당하는 계층과 실제 실행을 담당하는 계층으로 나뉨

- Control Plane (판단 / 통계 계층)
- Scheduler: 실행 준비 판단
- Dag Processor: Dag 파일 파싱
- Trigger: Deferrable Task / 이벤트 루프 실행
- API Server: Web UI, 상태 관리
- Execution Plane (실제 실행 계층)
- Executor/Worker: 실제 작업 수행
1-2. UI & API 변화
- 기존 구조: Flask 기반 Web UI, 모놀리식 아키텍처
- Frontend: React 기반 UI 도입으로 사용성 개선
- Backend: FastAPI 기반으로 성능 최적화
- 개선 포인트: DAG 탐색 용이성 확보, 로그 및 Grid 뷰의 가시성 증대
1-3. Executor 개념
Executor는 성능 옵션이 아니라, 운영 모델 선택이다.
=> "Task를 어떤 방식으로 실행할지 결정하는 운영 방식"
Airflow 3.0에서 Executor의 역할이 명확히 재정의됨
- Airflow의 역할: '무엇을 언제 실행할지'를 결정
- 실행 환경: 실제 작업 실행은 외부 실행 환경(Executor/Worker)이 담당
- Executor 종류:
- Local: 단일 머신에서 작업 실행 (개발 및 테스트 환경에 적합)
- Celery:
- 분산 작업 큐 기반, 수평 확장성 제공 (프로덕션 환경 적합)
- 부하가 몰릴때 Worker만 늘리면 되는 됨
- Kubernetes:
- K8s 기반 동적 리소스 할당, 컨테이너화된 작업 실행
- Task 마다 컨테이너를 분리하고 오토스케일링이 가능함
- 복잡한 운영체계가 있어서 운영 난이도가 증가함
2. DAG Parsing, Execution
2-1. DAG 파싱 프로세스
Airflow에서 DAG 파일이 어떻게 처리되고 실행되는지 이해하는 것은 효율적인 워크플로우 설계의 기본
- Dag Processor가 DAG 파일을 주기적으로 파싱하여 실행 가능한 태스크를
식별합니다. - 파싱 과정에서 DAG와 Task 객체 구조가 생성되고 메타데이터 DB에 저장됩니다.
- Scheduler는 스케줄에 따라 TaskInstance를 생성하고 실행 큐에 배치합니다.
2-2. DAG Parsing vs Task Execution
● 흔히 하는 실수
"DAG의 코드는 Task가 실행될때만 실행될거야." 라고 흔히 생각하게 되는데,
DAG 파싱에서도 실행되기 때문에 DAG내의 코드는 DAG 파싱 단계에서도 계속 돌게된다.
이 부분은 밑 2-3에도 정리해두었다.
- DAG 파싱: 실행 계획을 생성하는 과정 (Control Plane 담당)
- Task 실행: 실제 작업을 수행 (Executor와 Worker 담당)
- 특징: Airflow 3.0에서는 이 두 가지가 명확히 분리되어 있어 확장성을 가능하게
합니다.
2-3. Parse 타이밍과 주의점 (중요)
- 반복적 실행: DAG 파일은 Scheduler에 의해 주기적으로 파싱됨.
코드가 여러번 실행될 수 있음을 명심해야 함. - 선언적 접근: DAG는 실행 코드가 아니라 '실행을 설명하는 설계 선언문'
실행 로직과 정의를 분리해야 함 - 외부 API 호출 지양: 파싱 단계(Top-level)에서 외부 API를 호출하면 불필요한
부하와 성능 저하가 발생 - 무거운 연산 지양: 복잡한 계산이나 대용량 데이터 처리는 DAG 정의 밖인 Task
내부로 제한해야 함
3. 왜 Docker로 Airflow를 실행하는가?
● 쉬운 비유로 이해하기 (by Gemini)
EC2는 내가 장사를 하기 위해 빌린 '빈 상가 건물의 층'입니다.
Docker는 그 안에서 운영하는 '푸드트럭'입니다.
상가 바닥에 주방 기구를 직접 다 공사해서 설치하면(직접 설치), 나중에 다른 상가로 이사 가거나 점포를 늘릴 때 다 뜯어내고 새로 공사해야 합니다.
하지만 푸드트럭(Docker) 안에 모든 주방 설비를 갖춰놓으면, 상가(EC2)만 빌려서 트럭을 쏙 집어넣기만 하면 바로 영업을 시작할 수 있죠.
3-1. Docker 기반 실행의 장점
Docker는 실습 도구가 아니라 Airflow 3.0 운영 구조의 전제
- 멀티 컴포넌트: API Server, Scheduler, Executor, Worker 등 독립적 관리가
필요한 컴포넌트 구성에 적합 - 환경 재현성: 로컬과 클라우드 환경 간 일관성을 보장하여 "내 컴퓨터에선
되는데..." 문제를 방지 - 의존성 관리: Python 패키지, 시스템 라이브러리 등 복잡한 의존성을 컨테이너
이미지로 캡슐화합 - 배포 용이성: 컨테이너 오케스트레이션 도구(K8s 등)와 함께 사용해 확장성과
고가용성을 구축할 수 있음
3-2. Docker의 역할
- 격리: 각 컴포넌트를 독립된 컨테이너로 실행하여 리소스 충돌 방지 및 개별
스케일링 가능 (Scheduler/Worker 경계 명확) - 일관성: 모든 환경(Test, Prod, Local, QA 등등)에서 동일한 이미지 사용
- 확장성
- Worker 컨테이너의 쉬운 추가/제거
- Airflow는 항상 일정한 부하가 발생하는게 아니라
연말 정산, 월말 정산 등 특정 시기에 부하가 몰리면 이러한 Docker의 확장성의 이점을 누릴 수 있는것 - 특히 쿠버네티스랑 결합시 더욱 이점은 강해짐
- 표준화: 커뮤니티 표준 설정과 모범 사례 적용
4. 실습: Docker & Docker Compose 설치
4-1. 설치 단계
- Docker 설치: Ubuntu 패키지 저장소 설정 -> Docker Engine 설치
- 권한 설정: docker 그룹 생성 -> 현재 사용자에게 권한 부여 (sudo 없이 docker
사용) - Docker Compose: Compose 플러그인 설치
- 검증 단계: 버전 확인 및 테스트 컨테이너 실행
5. 실습: Airflow 3.0 Docker Compose 실행
5-1. 구조 및 서비스
공식 docker-compose.yaml 파일은 Airflow 3.0의 멀티 컴포넌트 아키텍처를
반영하여 각 서비스를 독립적인 컨테이너로 실행
- API Server: FastAPI 기반 백엔드
- Scheduler: TaskInstance 트리거
- Dag Processor: Dag 파싱
- Trigger: Deferrable Task / 이벤트 루프 실행
- Executor/Worker: 실제 태스크 실행
- Metadata DB: 상태 및 이력 저장
5-2. 초기 실행 흐름
- 환경 준비: 디렉토리 구조(dags, logs, plugins 등) 생성, 환경변수 설정
- DB 초기화: 메타데이터 테이블 생성, 기본 설정값 적용 (airflow-init)
- 계정 생성: Admin 사용자 설정, 권한 부여
- 서비스 시작: 컨테이너 의존성 순서대로 실행, 헬스체크
5-3. 아키텍처와 컨테이너 매핑
- 볼륨(Volume) 매핑:
- dags: DAG 파일 저장 위치
- logs: 로그 파일 저장
- plugins: 플러그인 저장
- config: 설정 파일 저장
- 네트워크(Network): 컨테이너 간 통신, 포트 매핑, 서비스 디스커버리
6. Web UI 접속 & Scheduler 로그 확인
6-1. Web UI 접속
- EC2의 Public IP와 설정한 포트(8085)를 통해 접속합니다.

6-2. Scheduler 로그 확인
- docker logs 명령어로 Scheduler 컨테이너의 로그를 확인하여 DAG 파싱 및
스케줄링 정보를 파악할 수 있습니다. - 로그 구조 및 핵심 포인트:
- DAG 파싱: 파일 변경 감지, 구문 오류 확인 등 메타 DB 저장 과정 모니터링
(문제 진단에 중요) - Task 상태: 상태 변화(queued -> running -> success/failed) 기록, 실패 시
상세 오류 제공 - 역할 분리: Scheduler는 계획만 생성하고 실제 실행은 Worker가 함을 로그로
확인 가능
- DAG 파싱: 파일 변경 감지, 구문 오류 확인 등 메타 DB 저장 과정 모니터링
7. 실습시 이해가 안되었던 명령어들 정리
1. 도커 설치 및 권한 설정
curl -fsSL https://get.docker.com | sudo sh
sudo usermod -aG docker $USER
newgrp docker
- 설명: EC2라는 빈 컴퓨터에 도커 엔진을 설치하는 과정입니다.
- 핵심: usermod와 newgrp는 "나 이제 sudo 안 붙이고도 도커 쓸래!"라고 컴퓨터에게 허락을 받는 과정입니다.
2. Airflow 환경 준비
mkdir -p 30-airflow/{dags,logs,plugins,config}
- 설명: 도커 컨테이너(가상 방)는 사라지면 데이터도 사라집니다. 그래서 실제 EC2 컴퓨터의 폴더와 도커 컨테이너 안의 폴더를 연결(볼륨 마운트)해줘야 합니다.
- dags: 내가 쓴 파이썬 코드를 넣는 곳.
- logs: 실행 기록이 쌓이는 곳.
3. 초기 실행 (Airflow-init)
docker network create de_net
docker compose up airflow-init
- de_net: 컨테이너들끼리 서로 통신할 수 있는 전용 전화선을 까는 것입니다.
- airflow-init: 이게 아주 중요합니다! Airflow가 처음 작동하려면 데이터를 저장할 DB 테이블을 만들고 관리자 계정(airflow/airflow)을 생성해야 합니다. 딱 한 번만 끝까지 실행되면 자동으로 꺼지는 서비스입니다.
4. 나머지 컴포넌트 기동 (본격 시작)
docker compose up -d
- 설명: 이제 스케줄러, 웹 서버, 워커 등 모든 부품을 한꺼번에 실행합니다. -d는 백그라운드에서 조용히 실행하라는 뜻입니다.
- 확인 (docker ps): 이 명령어를 치면 여러 개의 컨테이너가 떠 있을 텐데, API Server, Scheduler, Dag Processor 등이 각각 하나의 방으로 떠 있는 것을 볼 수 있습니다.
5. 실습 시나리오 이해하기 (가장 중요한 부분!)
시나리오 1: DAG가 왜 안 뜨지? (DAG Processor)
- 이유: 에러가 난 코드를 dags 폴더에 넣으면, DAG Processor라는 친구가 파싱(해석)하다가 "어? 이거 문법 틀렸는데?" 하고 멈춰버립니다.
- 로그 확인: 그래서 이때는 스케줄러가 아니라 dag-processor 로그를 봐야 범인을 잡을 수 있습니다.
임의로 DAG 파이썬 코드에 오류를 낸 다음 웹 UI를 확인하면 아래와 같은 에러를 확인할 수 있다.
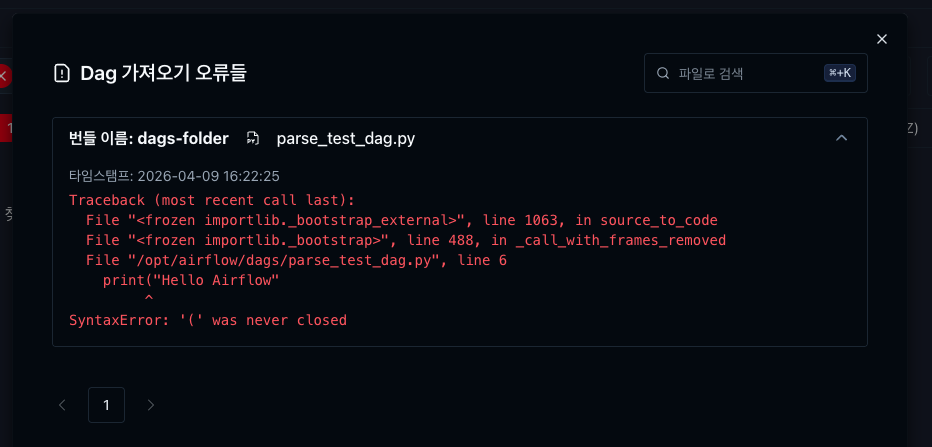
시나리오 2: 수정하면 어떻게 알지? (파일 감지)
- 이유: Airflow는 주기적으로 dags 폴더를 훑어봅니다.
- 핵심: docker logs -f로 로그를 켜놓고 파일을 저장하면, 로그 창에 실시간으로 "새로운 파일 감지됨! 파싱 시작!"이라는 글자가 올라오는 걸 볼 수 있습니다.
시나리오 3: 실행 흐름 (Scheduler -> Worker)
- 이유: UI에서 'Play' 버튼을 누르면 다음과 같은 일이 벌어집니다.
- Scheduler: "오케이, 지금 실행해야 하네? 줄 서(queued)!"라고 결정합니다.
- Worker: "줄 서 있는 거 내가 가져가서 실행할게(running)!"
- 로그: 로그를 보면 queued에서 running으로 상태가 바뀌는 순간이 찍힙니다. 이게 Airflow의 핵심 아키텍처인 **Control Plane(판단)**과 **Execution Plane(실행)**이 협업하는 과정입니다.
실제로 문법 에러를 수정후 다시 실행하면 아래와 같이 성공하는 것을 볼 수 있다.
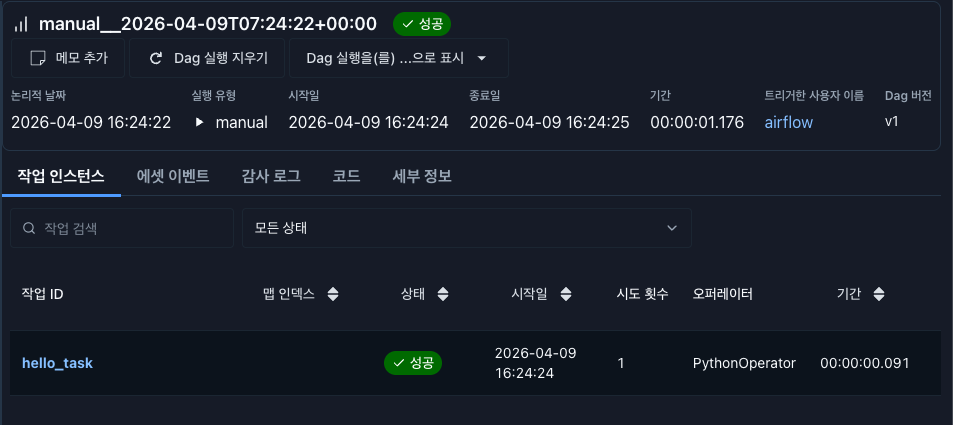
6. 테스트용 파이썬 파일 (parse_test_dag.py) 설명
실습을 진행할때 아래와 같은 테스트 파이썬 파일을 만들었는데 설명이 부족했다.
따라서 아래와 같은 추가적인 설명을 첨부한다.
def hello():
print("Hello Airflow")
with DAG(
dag_id="simple_dag", # UI에 표시될 이름
start_date=datetime(2024, 1, 1),
schedule="@daily", # 매일 한 번 실행
catchup=False, # 과거 기록은 무시해!
) as dag:
task = PythonOperator( # 파이썬 함수를 실행하는 작업 단위
task_id="hello_task",
python_callable=hello # 위에서 만든 hello 함수 실행
)
task
DAG 정의 영역
- dag_id="simple_dag": Airflow 세계에서 이 워크플로우를 식별하는 고유 이름입니다. Airflow UI에 이 이름으로 나타나며, 메타데이터 DB에도 이 이름으로 저장됩니다.
- start_date=datetime(2024, 1, 1): "이 작업은 과거 2024년 1월 1일부터 유효하다"는 선언입니다. Airflow는 이 날짜를 기준으로 실행 주기를 계산합니다.
- schedule="@daily": 스케줄링 모델입니다. 매일 자정(00:00)에 이 작업을 실행하겠다는 뜻입니다. Scheduler는 이 값을 보고 "아, 내일 자정에 TaskInstance를 만들어야겠군!" 하고 판단합니다.
- catchup=False: 만약 오늘(2026년) 처음 이 DAG를 켰는데 start_date가 2024년이라면, Airflow는 원래 밀린 2년 치 작업을 다 실행하려고 합니다. False로 설정하면 **"지나간 과거는 잊고 오늘부터만 잘하자"**라는 의미입니다.
Operator 영역: 실제 할일 정의
- PythonOperator: Airflow에는 "파이썬 함수 실행 전문 부품(Operator)"이 미리 만들어져 있습니다. 사용자는 "무엇을 실행할지"만 정의하면 됩니다.
- task_id="hello_task": 한 DAG 안에는 여러 개의 작업(Task)이 있을 수 있습니다. 그 작업들 사이에서 이 녀석을 부르는 이름입니다.
- python_callable=hello: "실제로 이 태스크가 실행될 때, 위에 정의해둔 def hello(): 함수를 호출해라"라는 연결 고리입니다.
실행 관계 및 아키텍처 연결
task
- 이 마지막 줄은 이 태스크를 DAG 안에 포함시키겠다는 선언입니다. (태스크가 여러 개라면 task1 >> task2 처럼 순서를 정해줄 수도 있습니다.)
'DataEngineer(DE) > Airflow 3.0 & DAG 개발 및 최적화' 카테고리의 다른 글
| Airflow 3.0과 DAG 개발 및 최적화 (6) - DAG 구조화 전략 & Dynamic Task Mapping (0) | 2026.04.11 |
|---|---|
| Airflow 3.0과 DAG 개발 및 최적화 (5) - Airflow 3.0 - XCom & Variable - AWS (0) | 2026.04.10 |
| Airflow 3.0과 DAG 개발 및 최적화 (4) - DAG 실행 제어 & Backfill (0) | 2026.04.09 |
| Airflow 3.0과 DAG 개발 및 최적화 (3) - First DAG-TaskFlow API (0) | 2026.04.09 |
| Airflow 3.0과 DAG 개발 및 최적화 (1) - Airflow 3.0 과정 목표 및 로드맵 (0) | 2026.04.08 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- de
- s3
- Data engineering
- Consumer DAG
- Glue
- Unity Catalog
- Data Dngineering
- Spark structured streaming
- Glue ETL
- DataSet
- AWS
- DAG
- AWS Glue Catalog
- Data Engineerring
- Daynamic Task
- docker
- airflow
- RDD
- Prodcuder DAG
- Databricks
- elasticip
- spark
- lakehouse
- Backfill
- 데이터파이프라인
- Data Pipeline
- kafka
- iceberg
- catchup
- lake house
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
글 보관함